
반복자, 컴포지트 패턴
반복자 패턴(Iterator Pattern)
반복 작업을 캡슐화 합니다.
컬렉션의 구현 방법을 노출하지 않으면서 집합체 내의 모든 항목에 접근하는 방법을 제공합니다.
컴포지트 패턴(Composite Pattern)
객체를 트리구조로 구성해서 부분-전체 계층구조를 구현합니다. 컴포지트 패턴을 사용하면 클라이언트에서 개별 객체와 복합 객체를 똑같은 방법으로 다룰 수 있습니다.
1. 객체마을 식당과 팬케이크 하우스의 합병
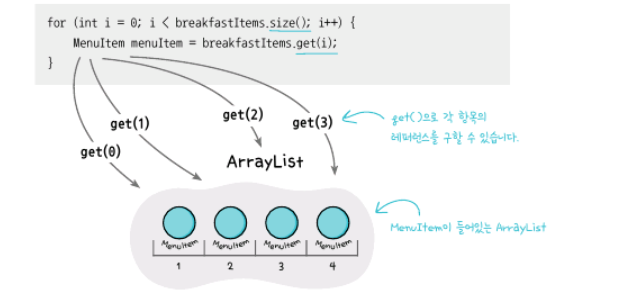
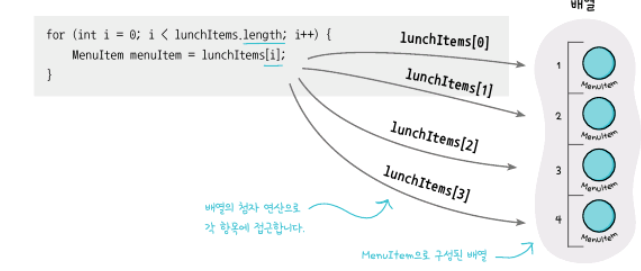
객체마을 식당과 팬케이크 하우스의 합병으로 메뉴판을 합쳐야 합니다. 하지만, 객체마을 식당은 Array를 사용해서 구현되어 있고 팬케이크 하우스는 ArrayList를 사용해서 구현되어 있죠.
참고로, Java에서 두 컬렉션는 유사하지만 다르며 가장 큰 차이는 Array는 배열 크기를 지정해야 하지만, ArrayList는 크기가 가변형 입니다.
각자의 클래스는 메뉴를 추가하는 코드 외에도 각 Array/ArrayList에 의존하는 다른 코드가 잔뜩 있습니다. 시퀀스를 맞추려면 코드를 엄청나게 많이 수정해야 하고 사이드 이펙트도 많이 발생할 거에요.
예를 들어, 같은 배열의 크기를 가져오는 코드인데도 Array는 length, ArrayList는 size() 이고 특정 요소를 가져오는 코드도 Array는 array[i], ArrayList는 array.get(i)와 같은 식입니다.
즉, 각자 다른 컬렉션 타입으로 구현되어 있는데 누구 하나를 고치자니 고칠 코드가 너무 많은데다가 발생할 사이드 이펙트 또한 걱정되는 상황인 것이죠.
이렇게 해도 됩니다. 되기는. 안될 건 없죠. 하지만 문제는 이렇게 되버리면 Waitress의 printMenu() 보면 알 수 있듯, 2종류의 가게를 합병이면 for문을 2번 돌아야하고 5종류의 가게를 합병하면 for문을 5번 돌아야 한다는 거죠.


2. 반복자 패턴 적용하기
그래서 Iterator(반복자)를 왜 적용하려고 하는건데 ?
똑같이 for문을 돌고 싶은데, 누구는 size와 get(i)으로 가져오고 누구는 length와 array[i]로 가져온다. 즉, 컬렉션이 다름에 따라서 지원되는 API가 다르다는 것이다.
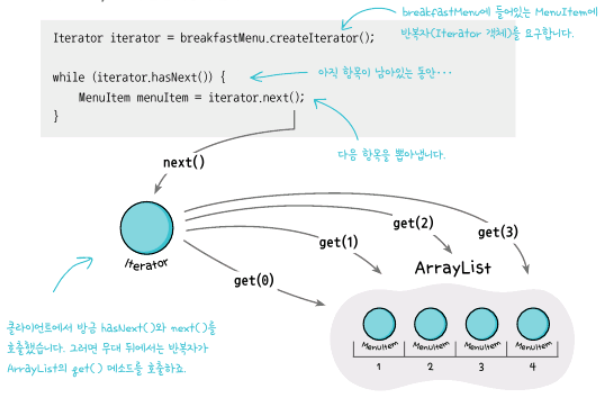
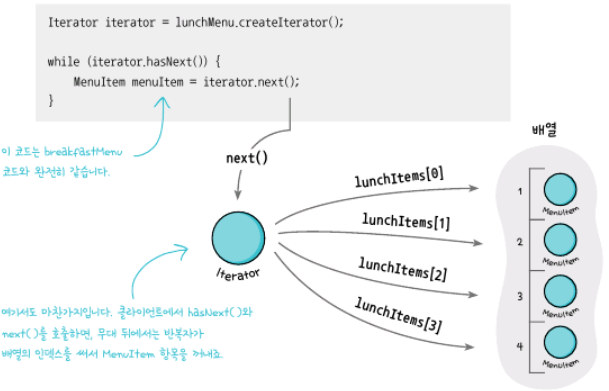
그래서, Iterator 인터페이스를 하나 만들고 그것에 맞는 클래스를 생성해서 똑같은 createIterator(), hasNext(), next() 라는 규격으로 맞춰서 하나로 관리할 수 있도록 하겠다는 것이다.
여기 코드에서는 hasNext()는 next()에 옵셔널을 적용해서 따로 구현하지 않았다.
Iterator 적용 전의 그림
Iterator 적용 후의 그림
3. 반복자 패턴 정리하기
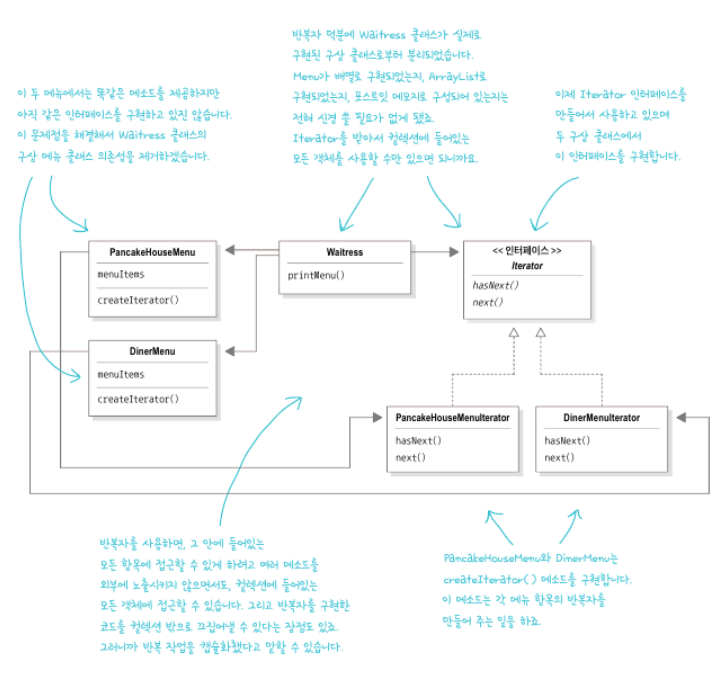
Waitress의 printMenu()의 문제점
인터페이스가 아닌 PancakeHouseMenu, ObjectDinerMenu라는 구상 클래스에 맞춰서 코딩하고 있습니다.
메뉴 항목의 목록을 Hashtable을 사용하는 방식으로 전환하려면 코드를 많이 수정해야 합니다.
종업원은 각 메뉴에서 항목의 컬렉션을 표현하는 방법을 알아야 하므로 캡슐화의 기본 원칙이 지켜지고 있지 않습니다.
코드가 중복됩니다. 서로 다른 순환문이 필요하고, 다른 메뉴를 추가로 사용하려면 순환문도 추가되어야 합니다.
Iterator 장착 하기
Iterator라는 인터페이스를 추가
ObjectDinerIterator, PancakeHouseIterator 구현
ObjectDinerMenu, PancakeHouseMenu 에서 내부 구조를 드러내던 getMenuItems() 을 삭제
ObjectDinerMenu, PancakeHouseMenu 에서 Iterator를 리턴하는 createIterator()를 구현
Iterator 장착 전의 종업원 코드
메뉴가 캡슐화되어 있지 않습니다. 객체마을 식당에서는 ArrayList를 쓰고, 팬케이크 하우스에는 Array를 쓴다는 사실을 누구나 알 수 있죠.
MenuItems을 대상으로 반복 작업을 하려면 2개의 순환문이 필요합니다.
Waitress가 [MenuItem]과 ArrayList에 직접 연결되어 있습니다.
Iterator 장착 후의 종업원 코드
메뉴가 캡슐화되어 있습니다. 종업원은 메뉴에서 메뉴 항목의 컬렉션을 어떤식으로 저장하는지 알 수 없습니다.
Iterator만 구현한다면 다형성을 활용해서 어떤 컬렉션이든 1개의 순환문으로 처리할 수 있습니다.
Waitress는 인터페이스(Iterator)만 알면 됩니다.
4. Swift의 IteratorProtocol
음, 당연?하게도 Swift에서 IteratorProtocol을 지원하고 있어요. associatedtype 으로 되어있는데 근데 문제는 이렇게 되어버리면 다형성을 어떻게 해결해야 되나 싶긴 하네요.
결국에는 규격이 다른 컬렉션을 사용한 부분에 대해서 그걸 하나의 반복자로 관리하고 싶어서 이 작업을 하게 되는건데, 위에 코드를 기준으로 하면 createIterator의 리턴값이 Iterator 프로토콜인데 리턴 값을 Swift에서 제공하는 IteratorProtocol을 사용하면 아래와 같은 에러 메시지가 발생하기 때문이지요.
이 부분은 좀 더 고민해보고 수정해놓아야 겠네요. 사실 기존에 Sequece, IteratorProtocol 프로토콜 같은 경우는 알고는 있었어요. Iterarot Pattern 관련한 것이 아니라 내가 커스텀으로 만드는 class 같은 것들을 for문을 돌도록 사용하기 위해서 같은 용도로 알고 있었거든요. 어찌 됐건, 새롭게 하나 또 배우게 되었네요.
하지만 알아둬야 될 점은, Swift의 컬렉션 타입(Array, Set, Dictionary)은 Collection 프로토콜을 준수하고 있고, Collection은 Sequence를 준수하고 있다는 거죠. 또 Sequence가 요구하는 메소드의 리턴타입이 IteratorProtocol이기 때문에 결론적으로 IteratorProtocol은 Swift의 컬렉션들을 이루는 근간이되는 프로토콜 중에 하나다 정도로 기억하고 있으면 될 것 같아요.
5. 단일 책임 원칙(SRP)
어떤 클래스가 바뀌는 이유는 하나뿐이어야 한다.
디자인 원칙 중에 단일책임원칙(Single Responsibility Principle)이라는 게 있습니다.
이걸 여기서 뜬금없이 왜 나왔냐면, 이런 겁니다.
지금 반복자 패턴을 사용해서 기존의 ObjectDinerMenu, PancakeHouseMenu는 건드리지 않고 모든 항목에 일일히 접근하는 작업을 ObjectDinerMenuIterator, PancakeHouseMenuIterator라는 반복자 객체가 맡고 있죠.
반복자 메소드 처리하는 역할이 클래스 내부로 들어가도 안되는 건 아니에요. 다만 그러면, 클래스의 역할이 2개로 늘어나겠죠. 1. 집합체 관리, 2. 반복자 메소드 처리 처럼요.
이렇게 되버리면, 클래스가 바뀌어야 할 이유가 증가하게 됩니다. 클래스 집합체가 변경되어도 바뀔 수 있고, 반복자 메소드 관련 기능이 변경되어도 바뀔 수 있는 거죠.
여기에 반복자 메소드 처리 기능 말고, 다른 기능이 더 있다고 해보죠. 그럼 클래스가 바뀔 수 있는 이유가 n개가 되는겁니다.
하지만, 클래스는 되도록 고치는 일은 피해야 하죠. 왜? 코드를 변경하다보면 온갖 문제가 생길 수 있으니까요. 100줄짜리 클래스가 아니라 1000줄, 10000줄 짜리 클래스면 더 문제가 발생할 가능성이 크겠죠.
그래서 하나의 역할은 하나의 클래스에서만 맡아야 된다고 하는 것입니다.
6. CafeMenu, CafeMenuIterator 추가하기
이번엔 Hashtable을 사용하는 카페메뉴를 추가합니다. key와 value값을 기반으로하고 컬렉션에 순서가 없기 때문에 next()가 약간 다릅니다.
7. 종업원 코드 개선하기
CafeMenu를 추가했습니다. 하지만, 문제가 좀 있죠. 메뉴가 3개가되면서 printMenu()를 3번이나 호출해야합니다.
이 말은 메뉴가 n개가 되면 n번 호출해야 된다는 거죠. 그리고 그 때마다 매번 종업원 코드를 변경해야 합니다.
클래스는 확장에는 열려 있어야 하지만 변경에는 닫혀 있어야 한다.(OCP)에 위배되지요.메뉴를 전부 합쳐서 1번만 호출하거나, 반복자를 하나만 만들 수는 없을까요?
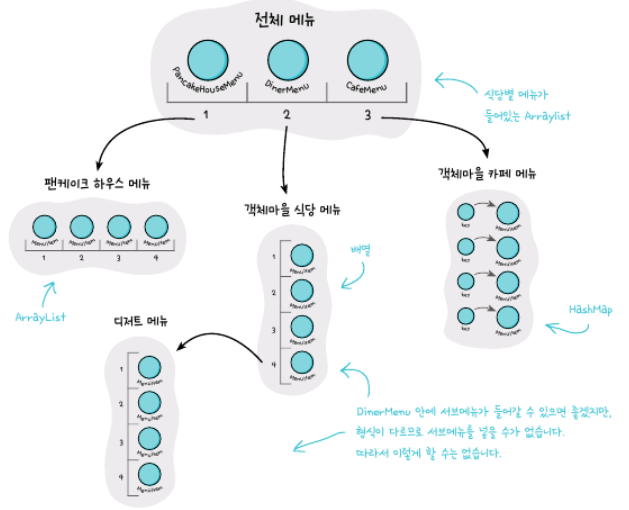
또, 메뉴안에 서브메뉴가 들어가있는 구조를 요청했습니다. 지금은 메뉴가 MenuItem으로 통일이 되어있기 때문에 그런 구조는 불가능할 것 같습니다.
메뉴, 서브메뉴, 메뉴 항목을 모두 넣을 수 있는 트리형태의 구조가 필요합니다.
자식이 있으면 노드(node), 없으면 잎(leaf)이라고 부릅니다.
각 메뉴에 있는 모든 항목을 대상으로 특정 작업을 할 수 있는 방법을 제공해야합니다.
메뉴에 껴있는 디저트 메뉴를 대상으로만 반복 작업을 할 수 있으면서도, 전체 메뉴를 대상으로 반복 작업도 할 수 있는 유연한 구조가 필요합니다.
8. 컴포지트 패턴 적용하기
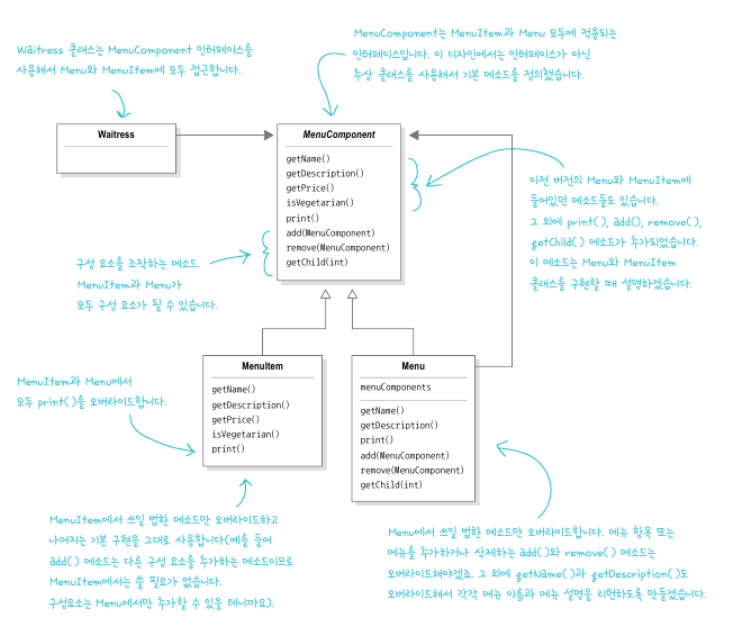
일단, 클라이언트 입장에서 개별 객체와 복합 객체가 똑같다고 생각을 하게 해줘야 합니다. 그러기 위한 공통 인터페이스인 MenuComponent를 정의합니다.
하지만, 일부 객체는 MenuComponent의 인터페이스 중에 안쓰는 메소드가 분명 있을 수 있어요. 그래서 protocol-extension 을 통해 기본 구현을 미리 해둡니다. java라면 추상클래스가 되겠죠.
다음은 만들어놓은 프로토콜을 준수하게 하는 것인데요. Menu와 MenuItem이 있는데, 아침메뉴/점심메뉴/저녁메뉴 같은 것들이 카테고리 역할을 하는 Menu 클래스이고 그 카테고리에 오늘의 스프/부리토 처럼 세부적으로 들어가는 녀석들이 MenuItem 입니다.
둘 다 MenuComponent 를 준수하고 있기 때문에 다형성에 따라서 클라이언트는 뭐가 뭔지 모르고 둘 다에게 접근할 수 있겠죠.
또, 오버라이드에 따라서 같은 함수를 다르게 처리해줄 수도 있습니다. 기본 구현이 되어있기 때문에 print() 함수는 구현하지 않아도 되지만 MenuItem의 print()와 Menu의 print()는 각각 동작이 다르죠.
물론, MenuItem에는 add(), remove(), get(i) 같은 것들이 없다는 것도 재밌는 점입니다. 어차피 쓸 일이 없으니 기본 구현만 해놓은 거죠. 사실 자식 노드(node)가 없기 대문에 그냥 잎(leaf)이라고 보는게 맞겠네요.
9. 컴포지트 패턴 정리하기
개별 객체와 복합 객체를 모두 담아 둘 수 있는 구조를 제공합니다. 그래서 클라이언트가 개별 객체와 복합 객체를 똑같은 방법으로 다룰 수 있습니다.
단일 책임 원칙(SRP)을 위배하는 대신에 투명성을 확보합니다. 무슨 말이냐면, 지금 MenuComponent에는 2가지 역할이 들어가 있죠. name, description 같은 잎(leaf)으로써의 기능과 add(), remove() 같은 자식들을 관리하는 기능입니다. 그러나 클라이언트는 투명하게 알 수 있어요. add(), remove()를 사용한다면 아 얘는 MenuItem이 아니라 Menu구나 하고 말이죠.
결론적으로 컴포지트 패턴은 SRP를 위배하지만 트리구조로 복합 객체와 잎을 똑같은 방식으로 처리하고 있죠. 이것은 상황에 따라 디자인 원칙을 적절하게 사용해야 함을 보여주는 대표 사례라고 할 수 있습니다.
자식에게 부모의 레퍼런스가 있을 수도 있습니다. 왜냐면, 삭제 같은 작업을 한다고 하죠. 그러면 내가 삭제해야하는 녀석까지 찾아가야하는데 그걸 찾아가기위해서 부모의 레퍼런스를 만들어 두기도 합니다.
하나 생각해보면 저장할 때, [MenuComponent]보다는 [Key값:MenuComponent] 같이 저장해서 삭제할 때 Key값으로 찾아간다던가 하는 방법이 있을 수 있겠어요. 다만, 그런 것도 있겠죠. tree 구조이기 때문에 해당 노드가 삭제되면 밑에 딸려있는 노드가 다 지워질 수 있죠. 그러면 어떻게 처리해야 할까요? 다 날려버리던지 이어붙이던지 해야겠죠. 그런 부분까지 잘 고려가 되어야 합니다.
Reference
https://www.hanbit.co.kr/store/books/look.php?p_code=B6113501223
Last updated