> For the complete documentation index, see [llms.txt](https://kickbell.gitbook.io/blog/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://kickbell.gitbook.io/blog/and/datastructure.md).
# 자료구조
### DataStructure(자료구조)란 ?
* 자료구조 == 데이터구조 == data structure
* 대량의 데이터를 효율적으로 관리할 수 있는 데이터의 구조를 의미
* 각각의 자료구조는 각자의 특징을 가지고 있다. 그런데 코드상에서 효율적으로 데이터를 처리해야 할 때, 해당 데이터의 특성에 따라 어떤 자료구조를 사용하느냐에 따라서 소프트웨어의 성능에 지대한 영향을 끼친다.

### Array(배열)
* 어떤 데이터를 연결된 공간에 넣을 때 사용한다.
* 장점
* index가 있기 때문에 내가 원하는 데이터로 직접적으로 빠른 접근이 가능하다.
* 단점
* index가 있기 때문에 중간 데이터를 삭제했을 때, 뒤에 있는 데이터들을 다 한칸씩 앞으로 이동해줘야 한다. index가 비어있으면 그건 배열이 아니기 때문이다.
* 배열을 생성시에 미리 길이를 지정해야 하기 때문에 데이터 추가, 삭제가 어렵다.

### Queue(큐)
```swift
import Foundation
struct Queue {
private var queue: [T] = []
mutating func enqueue(_ data: T) {
queue.append(data)
}
mutating func dequeue() -> T? {
if let _ = queue.first {
return queue.removeFirst()
}
return nil
}
}
var queue = Queue()
(1...10).map { String($0)}
.forEach {
queue.enqueue($0)
}
print(queue)
print(queue.dequeue() ?? "")
print(queue.dequeue() ?? "")
print(queue.dequeue() ?? "")
```
* 가장 먼저 넣은 데이터를 가장 먼저 꺼낼 수 있는 자료구조(FIFO)
* 은행의 번호표, 버스 줄서서 타기 등을 예로 들 수 있다.
* 데이터를 넣을때는 Enqueue, 꺼낼때는 Dequeue라고 한다.

* 기본 정책은 FIFO이지만, 다른 정책이 적용된 종류의 큐도 있다.
1. Queue(기본 큐)
* 가장 일반적인 큐, FIFO
2. LifoQueue
* 나중에 입력한 데이터가 가장 먼저 꺼내지는 구조(Stack처럼)
* LIFO(Last In Fast Out)
3. PriorityQueue(우선순위 큐)
* FIFO, LIFO 가 아니라 데이터를 넣을 때 우선순위를 같이 넣어서 그 순위를 기준으로 인큐/디큐하는 구조
* 튜플(priority: Int, data: Int) 형태로 사용되며 5등이 10등보다 좋은 것처럼 숫자가 낮은 것이 우선순위가 높은 것이다.
* Use
* 멀티 태스킹을 위한 프로세스 스케쥴링 방식을 구현하기 위해 많이 사용된다.(운영체제) 아마도 운영체제에서 자체적으로 PriorityQueue 같은걸 통해 프로세스의 우선순위를 배정하고 최대한의 스케쥴링 효율을 높이기 위해 사용하는 것 같다.
### LifoQueue(리포큐)
* 나중에 입력한 데이터가 가장 먼저 꺼내지는 정책을 가지고 있는 큐
* LIFO(Last In Fast Out)
```swift
import Foundation
struct LifoQueue {
private var queue: [T] = []
mutating func enqueue(_ data: T) {
queue.append(data)
}
mutating func dequeue() -> T? {
if let _ = queue.last {
return queue.removeLast()
}
return nil
}
}
var queue = LifoQueue()
(1...10).map { String($0)}
.forEach {
queue.enqueue($0)
}
print(queue)
print(queue.dequeue() ?? "")
print(queue.dequeue() ?? "")
print(queue.dequeue() ?? "")
```
### PriorityQueue(우선순위 큐)
* FIFO, LIFO 가 아니라 데이터를 넣을 때 우선순위를 같이 넣어서 그 순위를 기준으로 인큐/디큐하는 구조
* 튜플(priority: Int, data: Int) 형태로 사용되며 5등이 10등보다 좋은 것처럼 숫자가 낮은 것이 우선순위가 높은 것이다.
```swift
import Foundation
struct PriorityQueue {
private var priorityQueue: [(priority: Int, data: T)] = []
mutating func enqueue(_ tuple: (priority: Int, data: T)) {
priorityQueue.append(tuple)
}
mutating func dequeue() -> (Int, T)? {
guard !priorityQueue.isEmpty else { return nil }
priorityQueue.sort { $0.priority < $1.priority }
return priorityQueue.removeFirst()
}
}
var priorityQueue = PriorityQueue()
priorityQueue.enqueue((priority: 5, data: "hello"))
priorityQueue.enqueue((priority: 15, data: "bear"))
priorityQueue.enqueue((priority: 3, data: "zz"))
print(priorityQueue.dequeue() ?? (0, ""))
print(priorityQueue.dequeue() ?? (0, ""))
print(priorityQueue.dequeue() ?? (0, ""))
print(priorityQueue.dequeue() ?? (0, ""))
```
### Deque(덱, 양방향 순환큐)
* 큐인데 양쪽으로 입출력을 할 수 있는 자료구조
* 스택 + 큐의 느낌이라고 볼 수 있다.
*
```swift
public struct Deque {
private var array = [T]()
public var isEmpty: Bool {
return array.isEmpty
}
public var count: Int {
return array.count
}
public mutating func enqueue(_ element: T) {
array.append(element)
}
public mutating func enqueueFront(_ element: T) {
array.insert(element, at: 0)
}
public mutating func dequeue() -> T? {
if isEmpty {
return nil
} else {
return array.removeFirst()
}
}
public mutating func dequeueBack() -> T? {
if isEmpty {
return nil
} else {
return array.removeLast()
}
}
public func peekFront() -> T? {
return array.first
}
public func peekBack() -> T? {
return array.last
}
}
```
### Stack(스택)
```swift
import Foundation
struct Stack {
private var stackArray: [T] = []
mutating func push(data: T) {
stackArray.append(data)
}
mutating func pop() -> T? {
let data = stackArray.last ?? nil
stackArray.removeLast()
return data
}
}
var stack = Stack()
stack.push(data: 1)
stack.push(data: 2)
stack.push(data: 3)
print(stack.pop() ?? 0)
print(stack.pop() ?? 0)
print(stack.pop() ?? 0)
```
* 데이터를 제한적으로 접근할 수 있는 구조
* 한쪽 끝에서만 자료를 넣거나 뺄 수 있는 구조
* 넣을때는 push, 뺄때는 pop
* 큐: FIFO <-> 스택: LIFO
* 주로 사용 용도
* 스택 구조는 우리가 사용하는 운영체제의 프로세스 실행 구조의 가장 기본이다.
* 함수 호출시 프로세스 실행 구조를 스택과 비교해서 이해 필요

* 장점
* 구조가 단순해서, 구현이 쉽다.
* 데이터 저장/읽기 속도가 빠르다.
* 단점 (일반적인 스택 구현시)
* 데이터 최대 갯수를 미리 정해야 한다.
* 파이썬의 경우 재귀 함수는 1000번까지만 호출이 가능함
* 저장 공간의 낭비가 발생할 수 있음
* 미리 최대 갯수만큼 저장 공간을 확보해야 함(스택은 단순하고 빠른 성능을 위해 사용되므로, 보통 배열 구조를 활용해서 구현하는 것이 일반적임. 이 경우, 위에서 열거한 단점이 있을 수 있음)
### Linked List(링크드 리스트, 연결 리스트)
```swift
import Foundation
//왜 구조체로 안하고 클래스로 만들까?
//포인터 때문이 확실.. 구조체는 복사되니까.
class Node {
var data: Double
var next: Node?
init(data: Double, next: Node? = nil) {
self.data = data
self.next = next
}
}
var node1 = Node(data: 1)
var node2 = Node(data: 2)
node1.next = node2
var head = node1
//입력
func add(data: Double) {
var node: Node? = head
while node!.next != nil {
node = node?.next
}
node?.next = Node(data: data)
}
for index in 3...10 {
add(data: Double(index))
}
//출력
var node: Node? = head
while node!.next != nil {
print(node?.data ?? 0)
node = node!.next
}
print(node?.data ?? 0)
//중간에 데이터 추가하기
//1. 추가할 데이터 생성, 헤드값 초기화. 맨처음부터 다시 돌아야 되니까
var node3 = Node(data: 3.5)
node = head
//2. 어디에 넣을지 찾는 변수 추가
var search = true
//3. 어디에 넣을지 찾기.
// 그 이전까지는 주소값을 넣어주다가 3을 찾으면 종료시켜버림.
// 중요한 것은 1 + 주소값, 2 + 주소값, 3 -> 종료이기 때문에
// 4,5,6,7,8.. 같은애들애는 주소값이 없어. 즉, 미리 데이터가 다 들어가있는 상황에서
// 중간에 데이터를 삽입할때 쓰는 방법이라는 말임.
while search {
if node?.data == 3.0 {
search = false
} else {
node = node?.next
}
}
//4. 새로 넣을 데이터에 주소값 연결하기
// 자, 보면
// 지금 node.next는 원래 3->4 를 가리키던 주소값임.
// 그래서 일단 그걸 다른 변수에 담아놓는다.
let lastNext = node?.next
node?.next = node3 // 그리고 가리키는 값을 node3이 가리키도록 바꿔.
node3.next = lastNext // 그리고 마지막으로 node3이 4(lastNext)를 가리키도록 바꿔준다.
print("==================================================================")
//출력
node = head
while node!.next != nil {
print(node?.data ?? 0)
node = node!.next
}
print(node?.data ?? 0)
```
```swift
import Foundation
class Node {
var data: T
var pointer: Node?
init(data: T, pointer: Node? = nil) {
self.data = data
self.pointer = pointer
}
}
class NodeManager {
var head: Node?
var node: Node?
init(data: Int) {
self.head = Node(data: data)
}
func add(_ data: Int) {
node = self.head //처음 노드 할당
while node?.pointer != nil { //마지막 노드를 찾을때까지 반복
node = node?.pointer
}
node?.pointer = Node(data: data) //마지막 노드찾음 ㅇㅋ
}
//특정 데이터 삭제하기
func delete(_ data: Int) {
if self.head!.data == data { //1. 맨앞에 있는 애를 삭제하는 경우 (헤드를 삭제하는 경우)
self.head = self.head!.pointer
} else { //2. 마지막에 있는 애를 삭제하는 경우, 3. 중간에 있는 애를 삭제하는 경우
node = self.head
while node?.pointer != nil {
if node!.pointer!.data == data {
node?.pointer = node?.pointer?.pointer
} else {
node = node?.pointer
}
}
}
}
func search(_ data: Int) -> Node? {
node = self.head
while node != nil {
if node?.data == data {
return node
} else {
node = node?.pointer
}
}
return nil
}
//단순 전체 데이터 출력 용도 메소드
func desc() {
node = self.head // add하면서 node값이 달라졌으므로 첫노드로 다시 할당
while node != nil { //노드가 비어있지 않다면 반복
guard let unwrapNode = node else { return }
print(unwrapNode.data)
node = node?.pointer
}
}
}
let linkedList = NodeManager(data: 0)
print("데이터 추가 후 출력======================================================")
for data in 1...10 {
linkedList.add(data)
}
linkedList.desc()
print("4 삭제 확인======================================================")
linkedList.delete(4)
linkedList.desc()
print("10 삭제 확인======================================================")
linkedList.delete(10)
linkedList.desc()
print("3 노드 찾기======================================================")
let searchNode = linkedList.search(3)
print(searchNode!.data)
//while 문
//var count = 0
//while count < 10 { // 이 조건인 동안만 아래 스코프를 타라.
// print(count)
// count += 1
//}
```
* 배열의 최대 단점이 미리 길이를 지정해야 된다는 것이다. 새로운 공간을 만들어서 데이터를 추가한다고 해도 index는 4,5,6...이 아니라 0,1,2...부터 다시 시작하기 때문이다. 링크드 리스트는 그런 배열의 단점을 해결할 수 있다.
* 구성
* 노드(Node): 데이터값 + 포인터(다음데이터가 어딨는지 가리키는 주소)
* 포인터(pointer): 각 노드 안에서, 다음이나 이전의 노드와의 주소값을 가지고 있는 공간
* 제일 첫번째 노드를 head이라고 한다. 더블 링크드 리스트가 아니므로 tail은 없다.

* 장점
* 미리 데이터 공간을 미리 할당하지 않아도 됨
* 단점
* 데이터와는 별개로 포인터를 저장하기 위한 별도의 공간이 필요하므로 저장공간 효율이 좋진 않음.
* 앞에서 하나하나 찾아서 가야하므로 접근 속도가 느림.(이것 때문에 생긴 것이 더블 링크드 리스트)
* 상대적으로 복잡함. 중간 데이터 삭제시, 앞뒤 데이터의 포인터를 재연결해줘야 하는 부가적인 작업이 필요하기 때문.
### Double Linked List(더블 링크드 리스트)
```swift
import Foundation
class Node {
var data: T
var prev: Node?
var next: Node?
init(data: T, prev: Node? = nil, next: Node? = nil) {
self.data = data
self.prev = prev
self.next = next
}
}
class NodeManager {
var head: Node?
var node: Node?
init(data: Int) {
self.head = Node(data: data)
}
func add(_ data: Int) {
//1. 포인터를 타고 넘어갈 시작부분 할당
self.node = self.head
//2. 마지막 노드를 찾아감. while문을 통과하면 node는 데이터는 있고 다음 next는 nil인 마지막 노드를 가리키게 됨.
while self.node?.next != nil {
self.node = self.node?.next
}
//3. 마지막 노드에 데이터를 추가함. 생성자에 next = nil이 초기값으로 지정되어 있으므로 data만 추가하면 됨.
self.node?.next = Node(data: data)
}
func delete(_ data: Int) {
//1. 포인터를 타고 넘어갈 시작부분 할당
self.node = self.head
while self.node?.next != nil {
//2. 삭제하고자 하는 노드 찾기
if let unwrapData = self.node?.next?.data, unwrapData == data {
self.node?.next = self.node?.next?.next
return
}
self.node = self.node?.next
}
}
func search(_ data: Int) {
self.node = self.head
while self.node?.next != nil {
if let unwrapData = self.node?.data, unwrapData == data {
print("\(unwrapData) 에 해당하는 데이터값이 있습니다. ")
return
}
self.node = self.node?.next
}
print("해당하는 데이터값이 없습니다.")
}
func desc() {
//순회 전에 제일 처음 초기값 할당
self.node = self.head
//가장 마지막 데이터 이전까지 출력
while self.node?.next != nil {
if let data = self.node?.data {
print(data)
}
self.node = self.node?.next
}
//while문을 빠져나와서 마지막 데이터까지 출력하기
if let data = self.node?.data {
print(data)
}
}
}
let linkedList = NodeManager(data: 0)
print("\n==추가==")
(1...10).forEach { linkedList.add($0) }
linkedList.desc()
print("\n==검색==")
linkedList.search(4)
print("\n==삭제==")
linkedList.delete(3)
linkedList.desc()
```
```swift
import Foundation
class Node {
var data: T
var prev: Node?
var next: Node?
init(data: T, prev: Node? = nil, next: Node? = nil) {
self.data = data
self.prev = prev
self.next = next
}
}
class NodeManager {
var head: Node?
var tail: Node?
var node: Node?
init(data: Double) {
self.head = Node(data: data)
}
func add(_ data: Double) {
//1. 포인터를 타고 넘어갈 시작부분 할당
self.node = self.head
//2. 마지막 노드를 찾아감. while문을 통과하면 node는 데이터는 있고 다음 next는 nil인 마지막 노드를 가리키게 됨.
while self.node?.next != nil {
self.node = self.node?.next
}
//3. 마지막 노드에 데이터를 추가함. 생성자에 next = nil이 초기값으로 지정되어 있으므로 data만 추가하면 됨.
let newNode = Node(data: data)
self.node?.next = newNode
//4. 앞뒤로 포인터를 연결해줘야 하므로 prev에도 node를 할당
newNode.prev = self.node
//5. tail도 할당
self.tail = newNode
}
//연습3: 위 코드에서 노드 데이터가 특정 숫자인 노드 앞에 데이터를 추가하는 함수를 만들고, 테스트해보기
//- 더블 링크드 리스트의 tail 에서부터 뒤로 이동하며, 특정 숫자인 노드를 찾는 방식으로 함수를 구현하기
//- 테스트: 임의로 0 ~ 9까지 데이터를 링크드 리스트에 넣어보고, 데이터 값이 2인 노드 앞에 1.5 데이터 값을 가진 노드를 추가해보기
func insert(_ data: Double, beforeData: Double) {
self.node = self.tail //1. 뒤에서 부터 갈거니까 tail 할당
//2. beforeData앞에 넣을거니까 그걸 먼저 찾는다. 다르다면 한칸 앞으로 이동
while self.node!.data != beforeData {
self.node = self.node?.prev
if node?.prev == nil { //맨 앞까지 왔다면 해당 데이터가 없는거니까 그냥 break
print("해당 beforeData : \(beforeData) 는 존재하지 않습니다.")
return
}
}
//3. 여기까지 왔다면 self.node == beforeData를 갖는 노드라는 말이야. 이 애 앞에 새로운 데이터를 넣을거야.
let preNode = node?.prev
let newNode = Node(data: data)
//4. 새로만든 노드의 next 포인터 수정작업
preNode?.next = newNode
newNode.prev = preNode
//5. 새로만든 노드의 prev 포인터 수정작업
newNode.next = self.node
self.node?.prev = newNode
}
enum Direction {
case forward
case backward
}
func search(_ direction: Direction, _ data: Double) {
switch direction {
case .forward:
self.node = self.head
while self.node?.next != nil {
if let unwrapData = self.node?.data, unwrapData == data {
print("\(unwrapData) 에 해당하는 데이터값이 있습니다. ")
return
}
self.node = self.node?.next
}
case .backward:
self.node = self.tail
while self.node?.prev != nil {
if let unwrapData = self.node?.data, unwrapData == data {
print("\(unwrapData) 에 해당하는 데이터값이 있습니다. ")
return
}
self.node = self.node?.prev
}
}
print("해당하는 데이터값이 없습니다.")
}
func desc() {
//순회 전에 제일 처음 초기값 할당
self.node = self.head
//가장 마지막 데이터 이전까지 출력
while self.node?.next != nil {
if let data = self.node?.data {
print(data)
}
self.node = self.node?.next
}
//while문을 빠져나와서 마지막 데이터까지 출력하기
if let data = self.node?.data {
print(data)
}
}
}
let linkedList = NodeManager(data: 0.0)
print("\n==추가==")
(1...10).map { Double($0)}
.forEach{ linkedList.add($0) }
linkedList.desc()
print("\n==검색==")
linkedList.search(.forward, 5)
linkedList.search(.backward, 8)
print("\n==중간에 데이터 추가==")
linkedList.insert(5.5, beforeData: 6)
linkedList.desc()
```
* 변형된 형태의 링크드 리스트
* 링크드리스트의 구성이 노드와 포인터로 되어있다면, 더블 링크드 리스트는 포인터가 앞뒤로 2개다. 네이밍은 보통 prev, next 라는 식으로 한다. 포인터가 2개인 것만 생각하면 된다.
* 제일 첫번째 노드를 head, 제일 마지막 노드를 tail 이라고 한다.
* 기존의 링크드리스트의 단점이 head에서부터 쭉 찾아가야했음. 만약 정렬된 1만개의 데이터가 있는데 내가 찾는 데이터는 9999 라면, 기존의 링크드리스트는 1부터 찾아가야함. 그래서 이 문제를 해결하기 위해 더블 링크드 리스트가 나옴. tail이 있어 뒤에서부터 찾아갈 수가 있음.
* 장점
* 포인터가 양방향으로 연결되어 있어서 노드 탐색이 양쪽으로 모두 가능.
* 단점
* tail이 추가되었고, 중간에 데이터를 삭제/수정할 때 prev/next 포인터를 재연결해줘야 하는 작업이 링크드리스트보다 2배이므로 코드가 상대적으로 복잡함.

### Hash Table(해쉬 테이블)
```swift
import Foundation
/*
struct Car: Hashable {
var name: String
var price: Int
var codeName: String
}
struct Human: Hashable {
var age: String
var name: String
}
let car = Car(name: "그랜져", price: 30_000_000, codeName: "DH330")
let car2 = Car(name: "그랜져", price: 30_000_000, codeName: "DH330")
let human = Human(age: "35살", name: "김개똥")
//또 Hashable를 준수하면 구조체끼리도 비교할 수 있다.
print(car.hashValue) //-5235493752956059578
print(car2.hashValue) //-5235493752956059578, 내부데이터가 같기때문에 해시값도 똑같다.
print(human.hashValue) //1058167045924687262
print(car.hashValue == human.hashValue)
*/
//데이터를 저장할 해시 테이블 생성
var hashTable = (0..<8).map { _ in "" }
print(hashTable)
//데이터 값을 통해 키값을 반환
func getKey(data: String) -> Int {
return data.hashValue // String, Int등은 다 Hashable을 준수하고 있어서 hashValue라는 걸로 바로 만들 수 있다. 고정된 길이의 Int를 반환
}
//해시함수를 통해 저장할 해시 주소를 반환
func hashFunction(key: Int) -> Int {
return abs(key) % 8 //abs는 절대값. 음수키가 들어오면 양수로 바꿔주기 위해
}
func saveData(data: String, value: String) {
let key = getKey(data: data) //데이터 값을 통해 키값을 반환
let hashAddress = hashFunction(key: key) //해시함수를 통해 저장할 해시 주소를 반환
hashTable[hashAddress] = value //생성한 해시 테이블에 해시 주소를 index 값으로 해서 데이터를 저장
}
func readData(data: String) -> String {
let key = getKey(data: data)
let hashAddress = hashFunction(key: key)
return hashTable[hashAddress]
}
saveData(data: "사과", value: "10_000")
saveData(data: "포도", value: "20_000")
saveData(data: "수박", value: "30_000")
print(readData(data: "수박"))
print(hashTable)
typealias HashAddress = Int
```
```swift
import Foundation
/*
#### 6.1. Chaining 기법
- **개방 해슁 또는 Open Hashing 기법** 중 하나: 해쉬 테이블 저장공간 외의 공간을 활용하는 기법
- 충돌이 일어나면, 링크드 리스트라는 자료 구조를 사용해서, 링크드 리스트로 데이터를 추가로 뒤에 연결시켜서 저장하는 기법
*/
typealias hashKey = Int
typealias hashValue = String
typealias HashAddress = Int
//데이터를 저장할 해시 테이블 생성
var hashTable: [[(key: hashKey, value: hashValue)]] = (0..<8).map { _ in [(0, "")] }
hashTable.forEach { print($0) }
//데이터 값을 통해 키값을 반환
func getKey(data: String) -> Int {
return data.hashValue // String, Int등은 다 Hashable을 준수하고 있어서 hashValue라는 걸로 바로 만들 수 있다. 고정된 길이의 Int를 반환
}
//해시함수를 통해 저장할 해시 주소를 반환
func hashFunction(key: Int) -> Int {
return abs(key) % 8 //abs는 절대값. 음수키가 들어오면 양수로 바꿔주기 위해
}
func saveData(data: String, value: String) {
let key = getKey(data: data) //데이터 값을 통해 키값을 반환
let hashAddress = hashFunction(key: key) //해시함수를 통해 저장할 해시 주소를 반환
if let firstKey = hashTable[hashAddress].first?.key, firstKey == 0 {
//hashTable -> [[(key: hashKey, value: hashValue)]] 이고,
//hashTable[hashAddress] -> [(key: hashKey, value: hashValue)] 이다.
//첫번쨰 데이터의 키값이 0 이라는 것은 초기값 [(0, "")] 이라는 것이므로 아직 데이터가 들어가기 전이라는 말이다.
//그래서 데이터를 추가해준다.
hashTable[hashAddress] = [(key, value)]
} else {
//그렇지 않다는 것은 이미 데이터가 1개 들어가있다는 소리다. 충돌 Collision 난다는 거다.
//그리고 그걸 Chaining 방법으로 해결하려고 한다.
//원래대로라면 여기가 링크드리스트를 따로 구현해서 한다고 하는데, 지금은 hashTable -> [[(key: hashKey, value: hashValue)]]
//와 같은 식으로 그냥 배열과 튜플을 이용해서 for 문으로 같은 효과를 보면서 작업해 주려고 한다.
hashTable[hashAddress].append((key: key, value: value))
}
}
func readData(data: String) -> String {
let key = getKey(data: data)
let hashAddress = hashFunction(key: key)
if let firstKey = hashTable[hashAddress].first?.key, firstKey == 0 {
return "" //데이터 없음
} else {
for index in 0..
```swift
import Foundation
/*
#### 6.2. Linear Probing 기법
- **폐쇄 해슁 또는 Close Hashing 기법** 중 하나: 해쉬 테이블 저장공간 안에서 충돌 문제를 해결하는 기법
- 충돌이 일어나면, 해당 hash address의 다음 address부터 맨 처음 나오는 빈공간에 저장하는 기법
- 저장공간 활용도를 높이기 위한 기법
*/
typealias hashKey = Int
typealias hashValue = String
typealias HashAddress = Int
//데이터를 저장할 해시 테이블 생성
var hashTable: [(key: hashKey, value: hashValue)] = (0..<8).map { _ in (0, "") }
hashTable.forEach { print($0) }
//데이터 값을 통해 키값을 반환
func getKey(data: String) -> Int {
return data.hashValue // String, Int등은 다 Hashable을 준수하고 있어서 hashValue라는 걸로 바로 만들 수 있다. 고정된 길이의 Int를 반환
}
//해시함수를 통해 저장할 해시 주소를 반환
func hashFunction(key: Int) -> Int {
return abs(key) % 8 //abs는 절대값. 음수키가 들어오면 양수로 바꿔주기 위해
}
func saveData(data: String, value: String) {
let key = getKey(data: data) //데이터 값을 통해 키값을 반환
let hashAddress = hashFunction(key: key) //해시함수를 통해 저장할 해시 주소를 반환
// print(hashAddress, "Address")
if hashTable[hashAddress].key == 0 {
//데이터가 비어있다면
hashTable[hashAddress] = (key, value)
} else {
//데이터가 비어있지 않다면 충돌 Collision 난다는 거다.
//그리고 그걸 Linear Probing 방법으로 해결하려고 한다.
//선형 탐색?너낌으로 이후를 돌아주면 되는데.
for index in (hashAddress...hashTable.count-1) {
if hashTable[index].key == 0 {
//빈칸을 발견했으므로 여기다 충돌되는 데이터를 넣어주면 되겠다.
hashTable[index] = (key, value)
return //리턴 키워드 꼭 필요하다. 안해주면 이후 배열에 데이터 다들어감.
} else if hashTable[index].key == key {
//키가 같다는 것은 해당 데이터를 업데이트 한다는 것이다.
hashTable[index].value = value
return
}
}
}
}
func readData(data: String) -> String {
let key = getKey(data: data)
let hashAddress = hashFunction(key: key)
if hashTable[hashAddress].key == 0 {
return ""
} else {
for index in (hashAddress...hashTable.count-1) {
if hashTable[index].key == 0 {
return ""
} else if hashTable[index].key == key {
return hashTable[index].value
}
}
return ""
}
}
/*
4 Address
4 Address
====readData====
10_000
====totalData====
(key: 0, value: "")
(key: 0, value: "")
(key: 0, value: "")
(key: 0, value: "")
(key: -6740742047845731564, value: "10_000")
(key: 3996458706203432476, value: "20_000")
(key: 0, value: "")
(key: 0, value: "")
*/
saveData(data: "사과", value: "10_000")
saveData(data: "포도", value: "20_000")
print("\n====readData====")
print(readData(data: "사과"))
print("\n====totalData====")
hashTable.forEach { print($0) }
```
* 키(Key)에 데이터(Value)를 저장하는 데이터 구조, Swift에서는 딕셔너리로 바로 사용가능
* 보통 배열로 미리 Hash Table 사이즈만큼 생성 후에 사용 (공간과 탐색 시간을 맞바꾸는 기법 -> 해시테이블의 공간을 늘림으로써 키값이 중복되는 것에 대한 충돌(Collision)을 줄여서 추가적인 키값중복에 대한 자료구조나 로직을 사용하지 않게 한다는 말이다. 그래서 공간을 + 해서 시간을 - 한다는 뜻.)
* 구조
* 해쉬(Hash): 임의 값을 고정 길이로 변환하는 것을 말함.
* SHA(Secure Hash Algorithm, 안전한 해시 알고리즘)
* SHA256: 256비트로 항상 64자길이 값으로 리턴해준다.
* 해쉬 값(Hash Value): 해쉬(Hash) 과정으로 얻는 값.
* 해쉬 함수(Hash Function): 해쉬 값(Hash Value)을 원하는 대로 구현해 놓은 해시 함수에 넣으면 해시 테이블의 몇번째 index에 넣을지를 결정하는 해쉬 주소(Hash Address)를 반환한다.
* 해쉬 주소(Hash Address): 해쉬 테이블에 데이터를 넣을 index번호
* 해쉬 테이블(Hash Table): 키 값의 연산에 의해 직접 접근이 가능한 데이터 구조 (예를 들면 딕셔너리)
* 슬롯(Slot): 한 개의 데이터를 저장할 수 있는 공간

```swift
import Foundation
typealias HashKey = Int
typealias HashAddress = Int
typealias Value = String
//1. 배열로 미리 지정된 크기의 공간을 생성
var hashTable: [Value] = (0..<8).map { String($0) }
//2. 데이터를 지정된 해싱함수(데이터를 넣으면 고정된 길이를 반환하는 함수)로 넣어 해시키를 반환
func hashKey(data: String) -> HashKey {
return data.hashValue
}
//3. 해시 키를 넣으면 배열의 어느 index에 있는지 HashAddress를 반환함 .
func hashFunction(key: HashKey) -> HashAddress {
return key % 8
}
//4. data -> key, value -> 저장할 값이 된다. data로 key를 생성하고 그 key로 저장할 배열의 index를 반환하며, 해당 index에 미리 생성한 해시테이블에 value값을 넣는다.
func save(data: String, value: Value) {
let key = hashKey(data)
let hashAddress = hashFunction(key)
hashTable[hashAddress] = value
}
```
해시 함수는 임이의 길이를 갖는 메시지를 입력받아 고정된 길이의 해시값을 출력하는 함수입니다. 암호 알고리즘에는 키가 사용되지만, 해시 함수는 키를 사용하지 않으므로 같은 입력에 대해서는 항상 같은 출력이 나오게 됩니다.
* 충돌(Collision)
* 같은 해쉬 주소(Hash Address)에 2개 이상의 데이터가 들어가는 경우를 말한다. 여기서 해쉬 주소는 해시 테이블의 index값이라고 할 수 있겠다. 자세한 코드는 위에를 보면 알 수 있다.
* 데이터를 덮어쓴다면 충돌하지 않겠지만, 그렇지 않은 경우를 말한다. 예를 들면, data1 = 'Andy'와 data2 = 'Andrew'라는 데이터가 있을 때 파이썬의 ord() 함수를 이용해서 ord(data1\[0 ]), ord(data2\[0])를 실행하면 같은 A에 해당하는 65라는 아스키코드 값이 리턴된다. 이렇게 되면 다른 데이터에 같은 Hash Address값이 리턴되고 하나의 Hash Address값에 2개의 데이터가 들어가는 것이다. 이걸 충돌이라고 한다.
* 이런 문제를 해결하기 위해서 별도 자료구조가 필요하다.
* 충돌(Collision) 해결하기
\*
1. Chaining 기법
2. 충돌이 일어나면, 링크드 리스트라는 자료 구조를 사용해서, 링크드 리스트로 데이터를 추가로 뒤에 연결시켜서 저장하는 기법이다. 공간이 추가로 들어간다.
* 1) Linear Probing 기법
2) 충돌이 일어나면, 해당 hash address의 다음 address부터 맨 처음 나오는 빈공간에 저장하는 기법
3) 저장공간 활용도를 높이기 위한 기법
* 빈번한 충돌을 개선하는 기법
* 해쉬 함수을 재정의 및 해쉬 테이블 저장공간을 확대
* 예: 4개의 데이터를 저장한다고 했을때 보통 key % 8, rage(8)로 하면 충돌이 일어날 확률이 높으니 그 2배인 16으로 공간을 더 많이 잡는다.
* 공간으로 시간을 사는 셈이지만, 해쉬 테이블을 쓰는 이유가 충돌을 최대한 지양하고 O(1)로 쓰려고 하는것이므로 이게 제일 가장 간단하면서도 효율적인 방법이다.
```python
hash_table = list([None for i in range(16)])
def hash_function(key):
return key % 16
```
* 장점
* 어떤 키값에 대한 데이터가 있는지 여부만 판단하면 되기 때문에 데이터를 저장, 읽기 속도가 빠르다.
* 웹 사용시 사용하는 캐시메모리같은 것도 해시테이블을 사용하는 것이다. 해당 키값에 대응하는 데이터가 있는지 여부(중복확인)이 빠르기 때문에 어떤 이미지를 이미 다운받았으면 새로요청하지않고 변경된 데이터만 요청해서 웹브라우저의 사용성을 높이는 그런것들 말이다. 이걸 배열로 해야된다고 하면 0번 index부터 차례차례 데이터가 중복인지 순회해야 한다.
* 단점
* 충돌(Collision)이 발생할 수 있어 일반적으로 저장공간이 더 필요하다.
* **여러 키에 해당하는 주소가 동일할 경우 충돌을 해결하기 위한 별도 자료구조가 필요함**
* 주요 용도
* 검색이 많이 필요한 경우
* 저장, 삭제, 읽기가 빈번한 경우
* 캐쉬 구현시 (중복 확인이 쉽기 때문)
* 시간 복잡도
* 일반적인 경우(Collision이 없는 경우)는 O(1)
* 최악의 경우(Collision이 모두 발생하는 경우)는 O(n)
* 해쉬 테이블의 경우, 일반적인 경우를 기대하고 만들기 때문에, 시간 복잡도는 O(1) 이라고 말할 수 있음
### Tree(트리)
```swift
import Foundation
class Node {
var value: Int
var left: Node? = nil
var right: Node? = nil
init(value: Int) {
self.value = value
}
}
class NodeMgmt {
var rootNode: Node
init(rootNode: Node) {
self.rootNode = rootNode
}
func insert(value: Int) -> Int {
//루트노드를 생성하고 현재 노드로 할당
var currentNode: Node = self.rootNode
while true {
if value < currentNode.value {
//새로 들어온 데이터가 현재 노드보다 작으면 왼쪽
if currentNode.left == nil {
//currentNode.left가 nil이면 더이상 데이터가 없는것이니 새로운 노드를 만들어서 할당하면 끝
//while문을 빠져나가야 하니 break 필수
currentNode.left = Node(value: value)
return value
} else {
//currentNode.left가 nil이 아니라면 데이터가 더 있다는거니까 기준이 되는 노드를 바꿔줘서 다시 비교를 해야함.
currentNode = currentNode.left!
}
} else {
//새로 들어온 데이터가 현재 노드보다 크다면 오른쪽
if currentNode.right == nil {
currentNode.right = Node(value: value)
return value
} else {
currentNode = currentNode.right!
}
}
}
}
func search(value: Int) -> Bool {
//맨 위부터 내려가야되니까 초기값을 할당해준건데, 위와는 다르게 옵셔널로 해준이유는 while문을 끝까지 돌게 하려고 한거야.
//currentNode 가 nil이라는 말은
var currentNode: Node? = self.rootNode
while currentNode != nil {
guard let cNode = currentNode else { break }
if cNode.value == value {
return true
} else if value < cNode.value { //파라미터가 현재 노드의 값보다 작으면 왼쪽, 계속 순회
currentNode = cNode.left
} else {
currentNode = cNode.right //파라미터가 현재 노드의 값보다 크면 오른쪽, 계속 순회
}
//이렇게 들어갔다가 제일 마지막 노드는 left, right에 값이 없겠지 ? insert 에서 안넣어줬고 초기값이 nil 이니까
//그러면 while 문은 종료가 되고 이 다음줄로 넘어가서 false를 리턴하는거야.
}
return false
}
/*
delete는 좀 복잡하다. 이렇게 나눠서 생각해야 함
1. 삭제할 데이터가 있는지부터 확인
2. 데이터가 있다면 ? 3가지 경우의 수를 통해 작업, 없다면 리턴 false
- 삭제할 노드가 Leaf Node인 경우
- 삭제할 노드의 Chile Node 가 1개인 경우
- 삭제할 노드의 Chile Node 가 2개인 경우
*/
func delete(value: Int) -> Bool {
//삭제할 데이터가 있는지 여부를 판단한 Bool 타입 변수와 데이터를 삭제함에 따라서 브랜치를 새로 연결해줘야 하니
//부모노드도 가지고 있어야 하기 때문에 현재노드, 부모노드를 할당해준다.
var searched = false
var currentNode: Node? = self.rootNode
var parrentNode = self.rootNode
while currentNode != nil {
guard let cNode = currentNode else { break }
if cNode.value == value {
searched = true
break
} else if value < cNode.value {
parrentNode = cNode
currentNode = cNode.left
} else {
parrentNode = cNode
currentNode = cNode.right
}
}
//여기까지 왔다면 데이터가 있어서 break로 빠져나왔든, 또는 데이터는 없고 순회를 다해서 빠져나갔을 경우이다.
//만약에 데이터가 없다면 더 진행할 필요가 없으므로 여기서 처리해준다.
if searched == false { return false }
// 1. 삭제할 노드가 Leaf Node인 경우
if currentNode?.left == nil && currentNode?.right == nil {
// 지울 노드가 parrentNode 기준 왼/오른쪽이냐에 따라서 브랜치도 다르게 처리해주어야 하기 때문에 이렇게 나눠준다.
if value < parrentNode.value {
parrentNode.left = nil
} else {
parrentNode.right = nil
}
currentNode = nil //다 사용했으니 currentNode는 삭제
}
// 2. 삭제할 노드의 Chile Node 가 1개인 경우
/*
- 현재 노드가 왼쪽에만 Chile Node를 가지고 있을 경우
- ex.
10
5(c) 15
3 7
*/
if currentNode?.left != nil && currentNode?.right == nil {
if value < parrentNode.value {
parrentNode.left = currentNode?.left
} else {
parrentNode.right = currentNode?.left
}
currentNode = nil
}
/*
- 현재 노드가 오른쪽에만 Chile Node를 가지고 있을 경우
- ex.
10
5(c) 15
3 7
*/
if currentNode?.left == nil && currentNode?.right != nil {
if value < parrentNode.value {
parrentNode.left = currentNode?.right
} else {
parrentNode.right = currentNode?.right
}
currentNode = nil
}
// 3. 삭제할 노드의 Chile Node 가 2개인 경우
/*
#### 5.5.3. Case3-1: 삭제할 Node가 Child Node를 두 개 가지고 있을 경우 (삭제할 Node가 Parent Node 왼쪽에 있을 때)
#### 5.5.4. Case3-2: 삭제할 Node가 Child Node를 두 개 가지고 있을 경우 (삭제할 Node가 Parent Node 오른쪽에 있을 때)
* 기본 사용 가능 전략 (여기서는 1번 전략 사용)
1. **삭제할 Node의 오른쪽 자식 중, 가장 작은 값을 삭제할 Node의 Parent Node가 가리키도록 한다.**
2. 삭제할 Node의 왼쪽 자식 중, 가장 큰 값을 삭제할 Node의 Parent Node가 가리키도록 한다.
* 기본 사용 가능 전략 중, 1번 전략을 사용하여 코드를 구현하기로 함
- 경우의 수가 또다시 두가지가 있음
- 삭제할 Node가 Parent Node의 왼쪽에 있고, 삭제할 Node의 오른쪽 자식 중, 가장 작은 값을 가진 Node의 Child Node가
- Case3-1-1: 없을 때
- Case3-1-2: 있을 때
- 가장 작은 값을 가진 Node의 Child Node가 왼쪽에 있을 경우는 없음, 왜냐하면 왼쪽 Node가 있다는 것은 해당 Node보다 더 작은 값을 가진 Node가 있다는 뜻이기 때문임
*/
if currentNode?.left != nil && currentNode?.right != nil { //삭제할 노드의 Chile Node 가 2개인 경우
// 3-1,2 를 나눠서 작업하는데 밑에 가장 작은 노드가 자식을 가지냐에 따라서 또 2가지로 구분된다.
if value < parrentNode.value {
//#### 5.5.3. Case3-1: 삭제할 Node가 Child Node를 두 개 가지고 있을 경우 (삭제할 Node가 Parent Node 왼쪽에 있을 때)
var changeNode = currentNode?.right
var changeParrentNode = currentNode?.right
//여기부터는 강의 그림 봐라. 그냥 보면 다시봐도 절대 이해 안감.
while changeNode?.left != nil {
//오른쪽 자식을 순회하는 전략을 사용할건데, 이제 거기서 제일 작은애를 찾아야하니 계속 순회
changeParrentNode = changeNode
changeNode = changeNode?.left
}
//여기까지오면 이제 가장 작은노드를 찾은거고 그게 changeNode이다.
//그럼 여기서 이제 가장 작은 노드의 오른쪽에 자식이 있는지 없는지를 판단해서 작업한다.
//왼쪽에 자식이 있을 수는 없다. 왼쪽에 자식이 있다는 건 그녀석이 가장 작은 수라는 뜻이기 때문
//여기 작업은 changeParrentNode의 브랜치를 이어주는 작업
if changeNode?.right != nil {
changeParrentNode?.left = changeNode?.right //- Case3-1-1: 없을 때
} else {
changeParrentNode?.left = nil //- Case3-1-2: 있을 때
}
//여기 작업은 changeNode를 위로 올려서 재연결 해주는 작업
parrentNode.left = changeNode
changeNode?.left = currentNode?.left
changeNode?.right = currentNode?.right
} else {
//#### 5.5.4. Case3-2: 삭제할 Node가 Child Node를 두 개 가지고 있을 경우 (삭제할 Node가 Parent Node 오른쪽에 있을 때)
var changeNode = currentNode?.right
var changeParrentNode = currentNode?.right
while changeNode?.left != nil {
changeParrentNode = changeNode
changeNode = changeNode?.left
}
if changeNode?.right != nil {
changeParrentNode?.left = changeNode?.right
} else {
changeParrentNode?.left = nil
}
parrentNode.right = changeNode //이 부분만 다르다.
changeNode?.left = currentNode?.left
changeNode?.right = currentNode?.right
}
}
return true
}
}
//var rootNode = Node(value: 13)
//let bst = NodeMgmt(rootNode: rootNode)
//
//print("\n=== insert ===")
//print(bst.insert(value: 21))
//print(bst.insert(value: 15))
//print(bst.insert(value: 25))
//print(bst.insert(value: 42))
//print(bst.insert(value: 33))
//
//
//print("\n=== search ===")
//print(bst.search(value: 25))
// 0 ~ 999 숫자 중에서 임의로 100개를 추출해서 이진 탐색 트리에 입력, 검색, 삭제
// 0 ~ 999 중 100 개의 숫자 랜덤 선택
var bstNums: Set = []
while bstNums.count < 100 {
let randomInt = Int.random(in: 0...999)
bstNums.insert(randomInt)
}
print(bstNums)
// 선택된 100개의 숫자를 이진 탐색 트리에 입력, 임의로 루트 노드는 500을 넣기로 함 (0,1 같은걸 넣어버리면 트리가 한쪽으로 치우칠 수 있음)
let rootNode = Node(value: 500)
let bst = NodeMgmt(rootNode: rootNode)
for num in bstNums {
_ = bst.insert(value: num)
}
// 입력한 100개의 숫자 검색 (검색 기능 확인)
for num in bstNums {
if bst.search(value: num) == false { //100개를 검색했기 때문에 다 true를 리턴해야 하므로 false이면 검색 기능을 잘못 구현한 것임
print("search fail : \(num)")
}
}
// 입력한 100개의 숫자 중 10개의 숫자를 랜덤 선택
var deleteNums: Set = []
let tenbstNums = Array(bstNums)
while deleteNums.count < 10 {
let randomInt = tenbstNums.randomElement() ?? 0
deleteNums.insert(randomInt)
}
// 선택한 10개의 숫자를 삭제 (삭제 기능 확인)
for num in deleteNums {
if bst.delete(value: num) == false {
print("delete fail : \(num)")
}
}
```
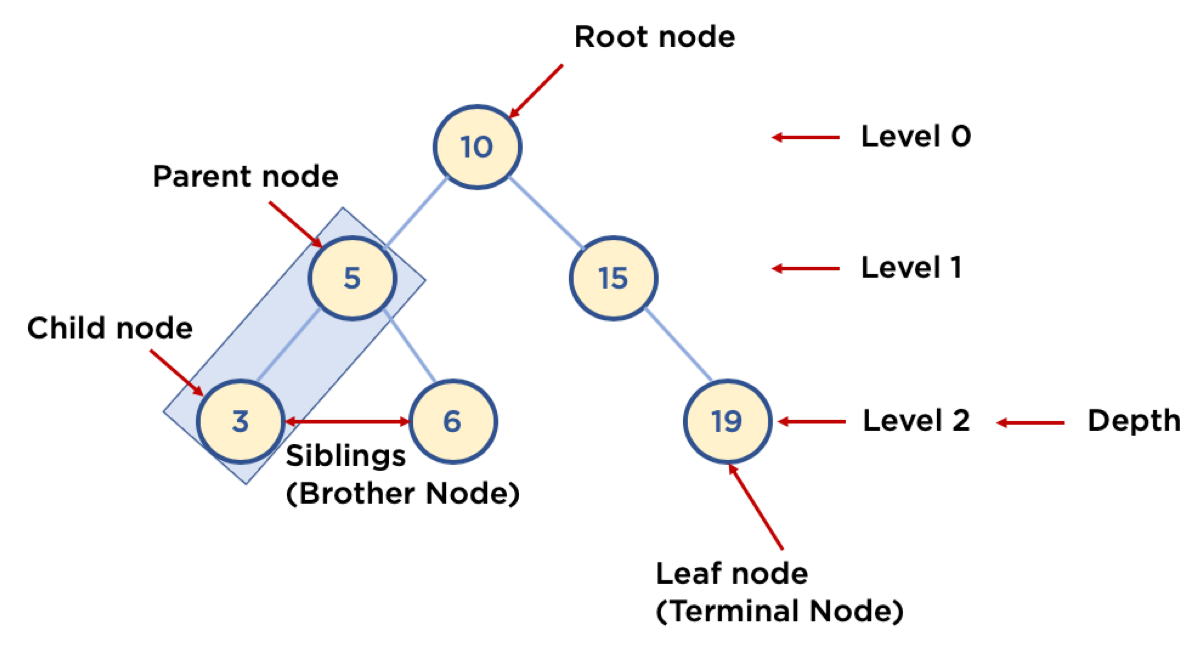
* Node와 Branch를 이용해서, 사이클(순환)을 이루지 않도록 구성한 데이터 구조
* 주요 용도
* 트리 중 이진 트리 (Binary Tree) 형태의 구조로, 탐색(검색) 알고리즘 구현을 위해 많이 사용됨
* 구조
* Node: 트리에서 데이터를 저장하는 기본 요소 (데이터와 다른 연결된 노드에 대한 Branch 정보 포함)
* Branch: 노드와 노드 사이를 가리키는 선
* Root Node: 트리 맨 위에 있는 노드
* Level: 최상위 노드를 Level 0으로 하였을 때, 하위 Branch로 연결된 노드의 깊이를 나타냄
* Parent Node: 어떤 노드의 다음 레벨에 연결된 노드
* Child Node: 어떤 노드의 상위 레벨에 연결된 노드
* Leaf Node (Terminal Node): Child Node가 하나도 없는 노드
* Sibling (Brother Node): 동일한 Parent Node를 가진 노드
* Depth: 트리에서 Node가 가질 수 있는 최대 Level
* 이진 트리(Binary Tree) vs 이진 탐색 트리 (Binary Search Tree)
* 이진 트리
* 자식 노드가 최대 2개인 트리
* 이진 탐색 트리 (Binary Search Tree, BST)
* 이진 트리 + 추가정책
* 항상 부모 노드의 자식인 왼쪽 차일드 노드는 부모 노드보다 작은 값을 가진다. 또 오른쪽 차일드 노드는 부모 노드보다 큰 값을 갖는다.
* 주로 검색용도로 제일 많이 쓰인다. 배열을 기준으로 했을때 배열은 10번째 데이터가 O(10)이 걸린다면, 이진 탐색 트리는 한번 검색할때마다 반토막씩 나니까 훠얼씬 빠르다.
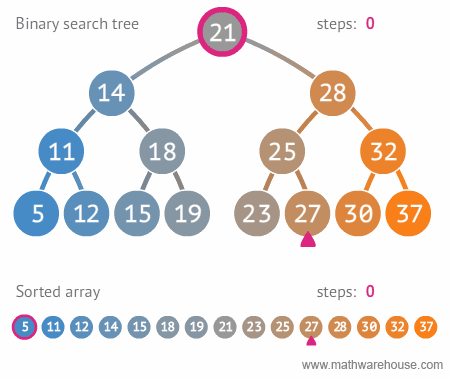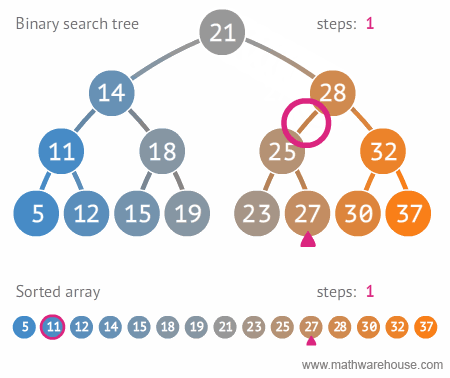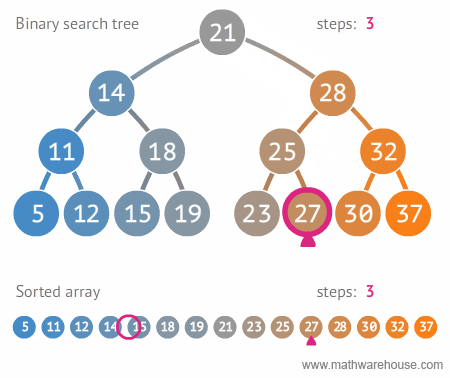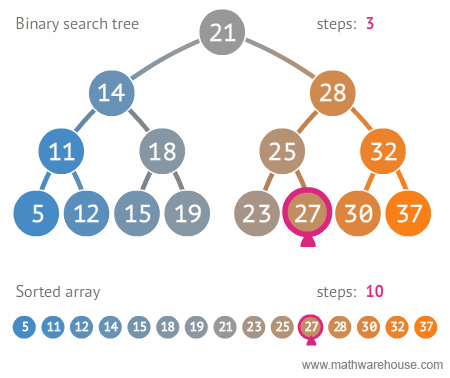
* 이진 탐색 트리의 시간 복잡도와 단점
* 시간 복잡도 (탐색시)
* depth (트리의 높이) 를 h라고 표기한다면, O(h)
* n개의 노드를 가진다면, $h=log\_2{n}$ 에 가까우므로, 시간 복잡도는 $O(log{n})$ (빅오 표기법에서 $log{n}$ 에서의 log의 밑은 10이 아니라, 2입니다.)
* 한번 실행시마다, 50%의 실행할 수도 있는 명령을 제거한다는 의미. 즉 50%의 실행시간을 단축시킬 수 있다는 것을 의미함
* 이진 탐색 트리 단점
* 평균 시간 복잡도는 $O(log{n})$ 이지만,
* 이는 트리가 균형잡혀 있을 때의 평균 시간복잡도이며, 다음 예와 같이 구성되어 있을 경우, 최악의 경우는 링크드 리스트등과 동일한 성능을 보여줌 $O(n)$
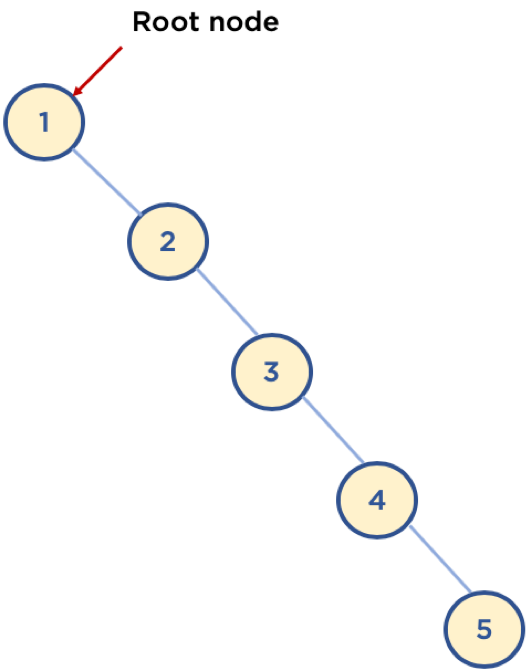
### Heap(힙)
```swift
import Foundation
class Heap {
var heapArray: [Int] = []
init(value: Int) {
self.heapArray.append(0) // 0 말고 옵셔널로 처리하거나 -1 같은걸로 처리하는 방법도 있긴 하겠는데,,
self.heapArray.append(value)
}
//제일 마지막에 입력된 데이터가 루트노드로 가게되고 그 데이터의 위와 아래를 바꿔줘야 되는지를 판단하는 메소드
//경우의 수 3가지
//1. 완전 이진 트리이므로 왼쪽 차일드 노드가 없는 경우 ( 바꿀 게 더이상 없으므로 끝냄 )
//2. 왼쪽만 차일드 노드가 있는 경우 ( 부모와 차일드 비교해서 부모보다 크다면? 바꿔주기 )
//3. 왼쪽 오른쪽 차일드 둘 다 있는 경우 ( 왼쪽과 오른쪽 차일드를 먼저 비교하고 그것 중에 큰 녀석을 부모와 비교해서 크다면? 바꿔주기 )
private func moveDown(_ poppedIndex: Int) -> Bool {
let leftChildIndex = poppedIndex * 2
let rightChildIndex = poppedIndex * 2 + 1
if leftChildIndex >= heapArray.count {
//1. 완전 이진 트리이므로 왼쪽 차일드 노드가 없는 경우 ( 바꿀 게 더이상 없으므로 끝냄 )
/*
15
10 8
5 4
이걸 왜 이렇게 하냐면, BST 같은 경우네는 Node라는 클래스를 가지고 구현을 했었잖아.
그래서 left, right가 옵셔널 이었고. 근데 얘는 배열로 구현한단 말이야. 그러면 당연히 중간에 빈데이터가 없어야돼. 그건 배열이 아니니까.
그럼 왜 이걸 이렇게 계산하냐? 자 보자. 위에 힙을 기준으로 heapArray.count는 6이야. 0번째를 포함해서. 즉 1번째 ~ 5번째를 가리키고 있는거지
근데 데이터 8을 기준으로 leftChildIndex는 3 * 2 = 6 이지? 그럼 지금 6이 있나? 없지.
데이터 5를 기준으로도 해보자 4 * 2 = 8 이다. 8 >= 6 이니까 왼쪽이 없는게 맞고
데이터 10을 기준으로 해보면 2 * 2 = 4 4 >= 6 이 아니니까 얘는 왼쪽 노드가 있는거지
데이터 4를 기준으로 해보면 4 * 2 + 1 = 9, 9 >= 6 이니까 얘도 왼쪽이 없는거고
뭐 이런 느낌이다. 쓰면서도 좀 헷갈리긴하는데 애매하면 그냥 외워. 큰 의미없을듯
*/
return false
} else if rightChildIndex >= heapArray.count {
//2. 왼쪽만 차일드 노드가 있는 경우 ( 부모와 차일드 비교해서 부모보다 크다면? 바꿔주기 )
if heapArray[poppedIndex] < heapArray[leftChildIndex] {
//2-1. poppedIndex인 내가 왼쪽 자식 인덱스값 보다 작다면 바꿔줘야되는 거니까 true
return true
} else { //2-2 크다면 안바꿔줘도 되니까 false
return false
}
} else {
//3. 왼쪽 오른쪽 차일드 둘 다 있는 경우 ( 왼쪽과 오른쪽 차일드를 먼저 비교하고 그것 중에 큰 녀석을 부모와 비교해서 크다면? 바꿔주기 )
if heapArray[leftChildIndex] > heapArray[rightChildIndex] {
//3-1. 왼쪽과 오른쪽을 비교해서 왼쪽이 크다면
if heapArray[poppedIndex] < heapArray[leftChildIndex] {
//3-2. 왼쪽의 큰 녀석인 내가 왼쪽 자식 인덱스값 보다 작다면 바꿔줘야되는 거니까 true
return true
} else {
//3-2 크다면 안바꿔줘도 되니까 false
return false
}
} else {
//3-1. 오른쪽이 크다면
if heapArray[poppedIndex] < heapArray[rightChildIndex] {
//3-2. 왼쪽의 큰 녀석인 내가 왼쪽 자식 인덱스값 보다 작다면 바꿔줘야되는 거니까 true
return true
} else {
//3-2 크다면 안바꿔줘도 되니까 false
return false
}
}
}
}
//데이터를 insert 할 때, 위와 아래를 바꿔줘야 되는지를 판단하는 메소드
private func moveUp(_ insertedIndex: Int) -> Bool {
if insertedIndex <= 1 { return false } //루트 노드(insertedIndex <= 1)라면 바꿀 필요 없으니 바로 리턴
let parentIndex = insertedIndex / 2
return heapArray[insertedIndex] > heapArray[parentIndex] //가장 마지막에 넣은 데이터가 부모데이터보다 크다면 위아래 스왑
}
func insert(_ value: Int) {
self.heapArray.append(value)
//가장 마지막 데이터의 index, 첫번째 0 넣은 길이도 포함해야 한다.
var insertedIndex = self.heapArray.count - 1
while moveUp(insertedIndex) {
let parentIndex = insertedIndex / 2
heapArray.swapAt(insertedIndex, parentIndex)
insertedIndex = parentIndex
}
}
func pop() -> Int {
let returnedData = heapArray[1] //최대값 또는 최소값 추출, 항상 루트 노드만 추출, 0번째는 항상 비어있으므로 제외
heapArray[1] = heapArray.removeLast() //마지막에 입력된 데이터를 삭제하면서 해당 리턴값을 루트 노드로 할당
var poppedIndex = 1 //pop된 index, 항상 루트노드부터 시작한다.
while moveDown(poppedIndex) { //moveDown이 true인 경우에만 신경쓰면 되니 false인 경우는 상관하지 않는다.
let leftChildIndex = poppedIndex * 2
let rightChildIndex = poppedIndex * 2 + 1
//1. 완전 이진 트리이므로 왼쪽 차일드 노드가 없는 경우 ( 바꿀 게 더이상 없으므로 끝냄 )
//-> 무시
//2. 왼쪽만 차일드 노드가 있는 경우 ( 부모와 차일드 비교해서 부모보다 크다면? 바꿔주기 )
if rightChildIndex >= heapArray.count {
//2. 왼쪽만 차일드 노드가 있는 경우 ( 부모와 차일드 비교해서 부모보다 크다면? 바꿔주기 )
if heapArray[poppedIndex] < heapArray[leftChildIndex] {
heapArray.swapAt(poppedIndex, leftChildIndex) //바꿔주고,
poppedIndex = leftChildIndex //계속 순회를 해야되니까 index를 바꿔준 child로 교체
}
} else {
//3. 왼쪽 오른쪽 차일드 둘 다 있는 경우 ( 왼쪽과 오른쪽 차일드를 먼저 비교하고 그것 중에 큰 녀석을 부모와 비교해서 크다면? 바꿔주기 )
if heapArray[leftChildIndex] > heapArray[rightChildIndex] {
//3-1. 왼쪽과 오른쪽을 비교해서 왼쪽이 크다면
if heapArray[poppedIndex] < heapArray[leftChildIndex] {
heapArray.swapAt(poppedIndex, leftChildIndex) //바꿔주고,
poppedIndex = leftChildIndex //계속 순회를 해야되니까 index를 바꿔준 child로 교체
}
} else {
//3-1. 오른쪽이 크다면
if heapArray[poppedIndex] < heapArray[rightChildIndex] {
heapArray.swapAt(poppedIndex, rightChildIndex)
poppedIndex = rightChildIndex
}
}
}
}
return returnedData //꼭 변수선언을 해줘야하는게 heapArray[1]에 수정작업이 이뤄지기 때문
}
}
print("\n===코드 검증===")
let heap = Heap(value: 15)
heap.insert(10)
heap.insert(8)
heap.insert(5)
heap.insert(4)
print(heap.heapArray)
print("\n===20 insert===")
heap.insert(20)
print(heap.heapArray)
print("\n===pop===")
heap.pop()
print(heap.heapArray)
```
* 데이터에서 최대값과 최소값을 빠르게 찾기 위해 고안된 자료구조
* 위의 BST나 Tree와 뭐가 다르냐? 이건 오로지 최대값/최소값을 빠르게 검색하기 위한 자료구조이다.
* 트리의 한 종류로 완전 이진 트리이다.
* 힙을 사용하는 이유
* 배열에 데이터를 넣고, 최대값과 최소값을 찾으려면 O(n) 이 걸리지만, 힙에 데이터를 넣고, 최대값과 최소값을 찾으면, $O(log n)$ 이 걸림
* 우선순위 큐와 같이 최대값 또는 최소값을 빠르게 찾아야 하는 자료구조 및 알고리즘 구현 등에 활용됨
* 구조
* 힙은 최대값을 구하기 위한 최대 힙(Max Heap) 와 최소값을 구하기 위한 최소 힙(Min Heap) 로 분류됨.
* 힙은 다음과 같이 두 가지 정책을 가지고 있는 자료구조임
1. 부모 노드의 값은 자식 노드의 값보다 크거나 같다. (최대 힙의 경우) 만약 최소 힙이라면 반대이다. 작거나 같다.
2. 완전 이진 트리 형태를 가진다. (왼쪽아래부터 데이터를 넣는다.)
* 완전 이진 트리(Complete Binary Tree)
* 왼쪽 아래 부터 데이터를 채워지는 트리
* 이진 트리 이므로 자식노드가 최대 2개를 갖는다.
* 힙(Heap)과 이진 탐색 트리(Binary Search Tree)의 공통점과 차이점
* 공통점
* 힙과 이진 탐색 트리는 모두 이진 트리임 ( 자식이 최대 2개라는 말이다. )
* 차이점
* 힙은 각 부모 노드의 값이 자식 노드보다 크거나 같음(Max Heap의 경우, Min Heap은 반대)
* BST는 는 왼쪽 자식 노드의 값이 가장 작고, 그 다음 부모 노드, 그 다음 오른쪽 자식 노드 값이 가장 큼
* 힙은 위와 같은 조건은 없음. 힙의 왼쪽 및 오른쪽 자식 노드의 값은 오른쪽이 클 수도 있고, 왼쪽이 클 수도 있음
* BST는 검색을 위한 구조이고 힙은 최대/최소값을 빠르게 찾기위한 구조 중 하나로 이해하면 됨
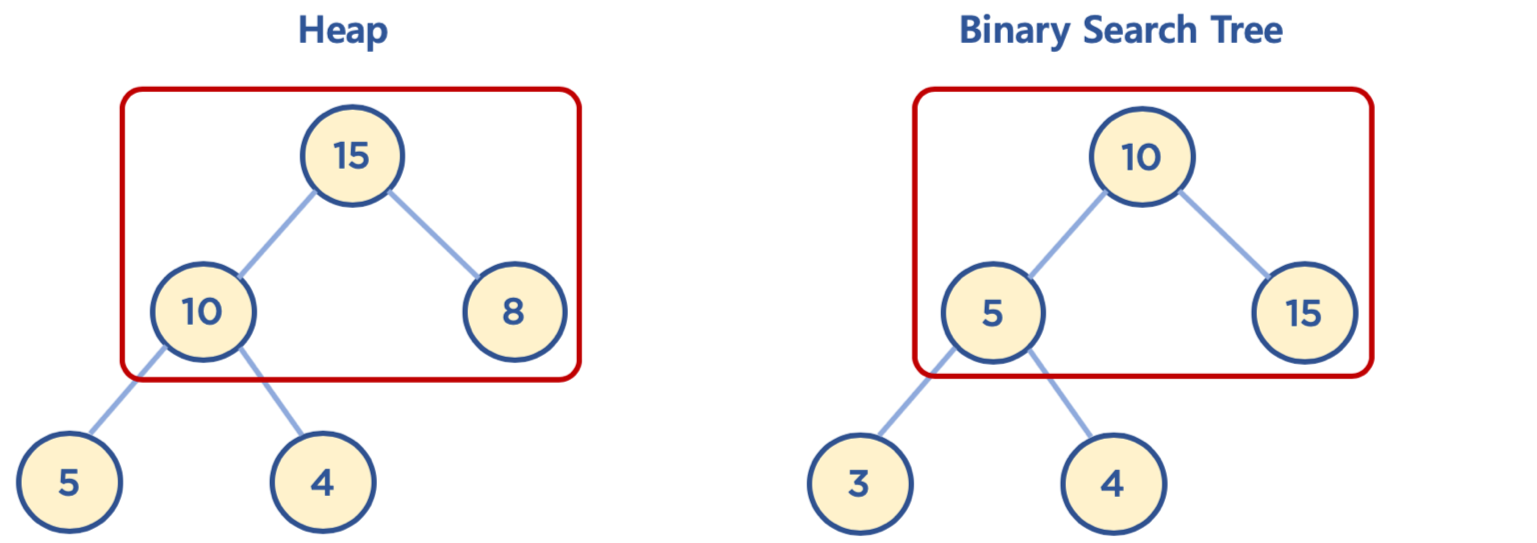
* 힙 구현(배열로 구현, 왜?)
* 일반적으로 힙 구현시 배열 자료구조를 활용함, 왜?
* 완전 이진 트리 형태로 구현되어 있어서 중간에 빈값도 없고 하기 때문에 index로 특정 부모, 자식 노드를 특정할 수 있음. 대박임.
* 배열은 인덱스가 0번부터 시작하지만, 힙 구현의 편의를 위해, root 노드 인덱스 번호를 1로 지정하면, 구현이 좀더 수월함, 왜? ( 아래에서 부모, 왼쪽자식, 오른쪽 자식 인덱스번호를 계산하는 공식이 있는데 0부터 시작해 버리면 0 / 2, 0 \* 2 가 다 0 이 되버리기 때문에 더 복잡해짐 )
* index를 강제로 바꾼다거나 그런건 아니고 그냥 배열의 0번째에는 아무것도 안넣어버리고 index 1번째 부터 데이터를 넣겠다는 말임.
> 공식
>
> * 부모 노드 인덱스 번호 = 자식 노드 인덱스 번호 / 2
> * 왼쪽 자식 노드 인덱스 번호 = 부모 노드 인덱스 번호 \* 2
> * 오른쪽 자식 노드 인덱스 번호 = 부모 노드 인덱스 번호 \* 2 + 1
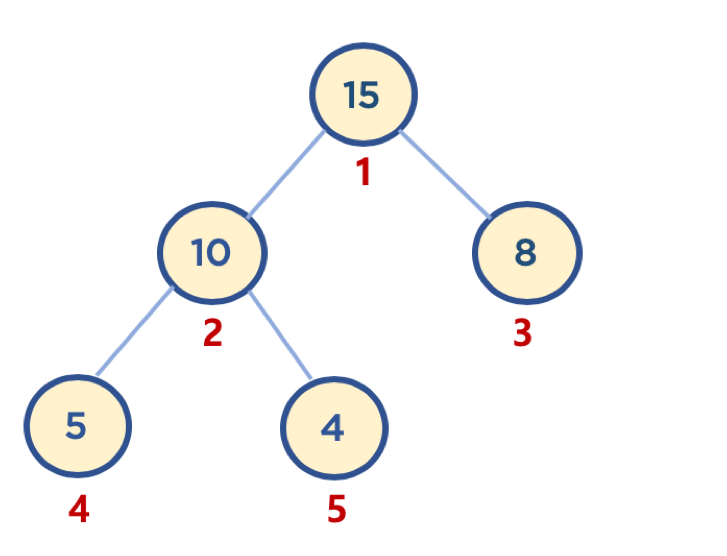
* 시간 복잡도
* depth (트리의 높이) 를 h라고 표기한다면,
* 최소값 또는 최대값을 빼는 연산은 O(1)이지만, 힙의 성질에 맞게 재구조화(heapify)하는 과정이 필요하다.
* 근데, 이진트리이므로 반땡이긴 하지만 삽입 또는 삭제시 삽입은 맨끝에서 루트까지 올라올 수 있고 삭제는 맨위에서 맨아래까지 내려올 수 있다.
* 따라서 시간 복잡도는 $h = log\_2{n} $ 에 가까우므로, 시간 복잡도는 $ O(log{n}) $ 이다.
* 참고: 빅오 표기법에서 $log{n}$ 에서의 log의 밑은 10이 아니라, 2입니다.
* 한번 실행시마다, 50%의 실행할 수도 있는 명령을 제거한다는 의미. 즉 50%의 실행시간을 단축시킬 수 있다는 것을 의미함
### Graph(그래프)
* 실제 세계의 현상이나 사물을 정점(Vertex) 또는 노드(Node)와 간선(Edge)로 표현하기 위해 사용하는 자료구조
* 트리(Tree) 또한 그래프의 하나이다.
* 가장 어려운 부분이다. 대학원에서도 그래프 관련한 논문이 많다고 한다.
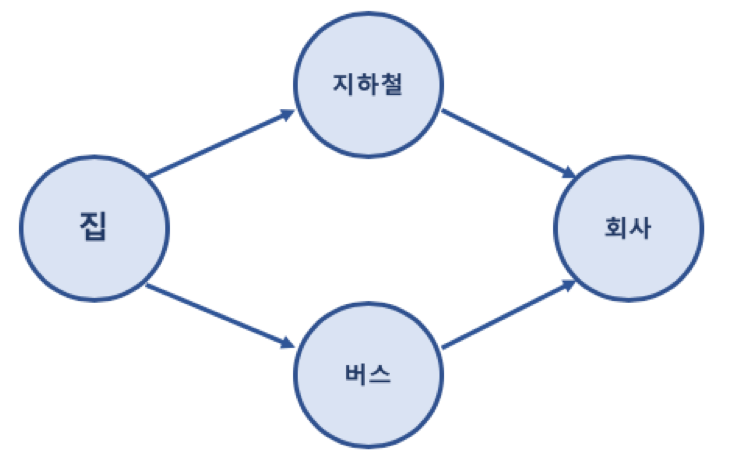
* 그래프 관련 용어
* 노드 (Node): 위치를 말함, 정점(Vertex)라고도 부른다.
* 간선 (Edge): 노드를 연결한 선이(link 또는 branch 라고도 함)
* 인접 정점 (Adjacent Vertex):
* 간선으로 직접 연결된 노드
* (집)-(지하철)이면 집과 지하철 2개가 인접한 노드라고 부른다.
* 참고 용어
* 무방향 그래프 (Undirected Graph): 간선에 화살표가 없는 그래프
* 방향 그래프 (Directed Graph): 간선에 화살표가 있는 그래프
* 정점의 차수 (Degree):
* 무방향 그래프에서 하나의 정점에 인접한 정점의 수
* 위에 사진을 기준으로 무방향그래프라고 가정하면 (지하철)의 차수는 2
* 진입 차수 (In-Degree):
* 방향 그래프에서 외부에서 들어오는 간선의 수
* 위에 사진을 기준으로 (지하철)의 진입 차수는 1
* 진출 차수 (Out-Degree):
* 방향 그래프에서 외부로 향하는 간선의 수
* 위에 사진을 기준으로 (지하철)의 진출 차수는 1
* 경로 길이 (Path Length):
* 경로를 구성하기 위해 사용된 간선의 수
* (집)->(지하철)->(회사) 라는 경로가 있을 때, 경로가 완성되기 까지 필요한 간선의 수는 2
* 단순 경로 (Simple Path):
* 처음 정점과 끝 정점을 제외하고 중복된 정점이 없는 경로
* (집)->(지하철)->(회사)->(버스)->(회사) 라는 경로가 있다면 끝 정점은 회사인데 경로가 중복되어 있다. 이런 중복된 경로를 제외한 경로를 단순 경로라고 한다.
* 다만, (처음 정점과 끝 정점을 제외하고) 라는 말이 있듯이 집에서 시작해 집에서 끝났다면 그건 단순경로가 맞다. 예를 들어, (집)->(지하철)->(회사)->(버스)->(집) 이라는 경로는 집이 2회 나오지만 예외적으로 단순 경로이다.
* 사이클 (Cycle):
* 단순 경로의 시작 정점과 종료 정점이 동일한 경우(밑에 그림으로 설명)
* 위에서의 (집)->(지하철)->(회사)->(버스)->(집) 을 사이클 이라고 부른다.
* 그래프의 종류
* 무방향 그래프 (Undirected Graph)
* 방향이 없는 그래프
* 간선을 통해, 노드는 양방향으로 갈 수 있음
* 보통 노드 A, B가 연결되어 있을 경우, (A, B) 또는 (B, A) 로 표기
* 무방향 그래프 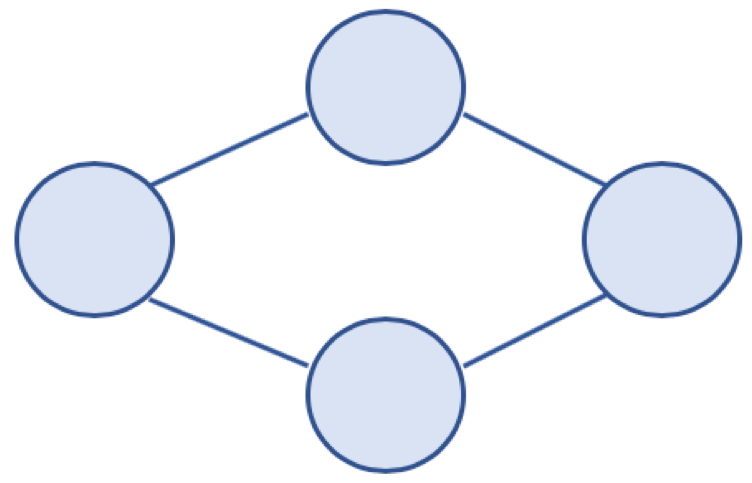
* 방향 그래프 (Directed Graph)
* 간선에 방향이 있는 그래프
* 보통 노드 A, B가 A -> B 로 가는 간선으로 연결되어 있을 경우, \ 로 표기 (\ 는 B -> A 로 가는 간선이 있는 경우이므로 \ 와 다름)
* 방향 그래프 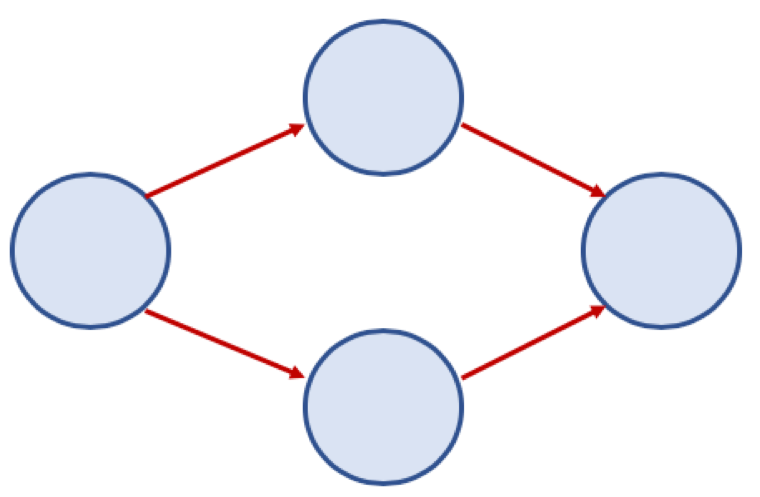
* 가중치 그래프 (Weighted Graph) 또는 네트워크 (Network)
* 간선에 비용 또는 가중치가 할당된 그래프
* 위에 그림처럼 집->지하철->회사, 집->버스->회사라고 하면 이해하기 쉽게는 거리느낌이다.
* 집에서 지하철역까지 200미터, 버스정류장까지 400미터 같은 느낌이므로 가중치가 합쳐서 300미터인 밑에 경로가 더 좋은 경로이다.
* 가중치 그래프 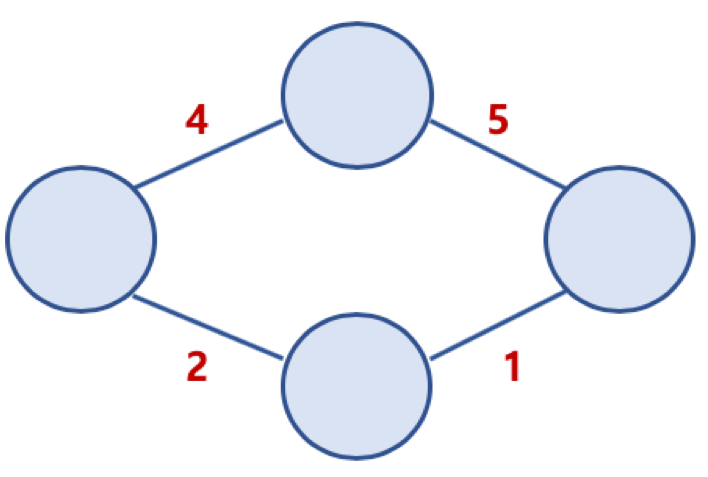
* 연결 그래프 (Connected Graph) 와 비연결 그래프 (Disconnected Graph)
* 연결 그래프 (Connected Graph)
* 무방향 그래프에 있는 모든 노드에 대해 항상 경로가 존재하는 경우
* 모든 노드가 항상 간선으로 연결되어 있다는 뜻
* 비연결 그래프 (Disconnected Graph)
* 무방향 그래프에서 특정 노드에 대해 경로가 존재하지 않는 경우
* 비연결 그래프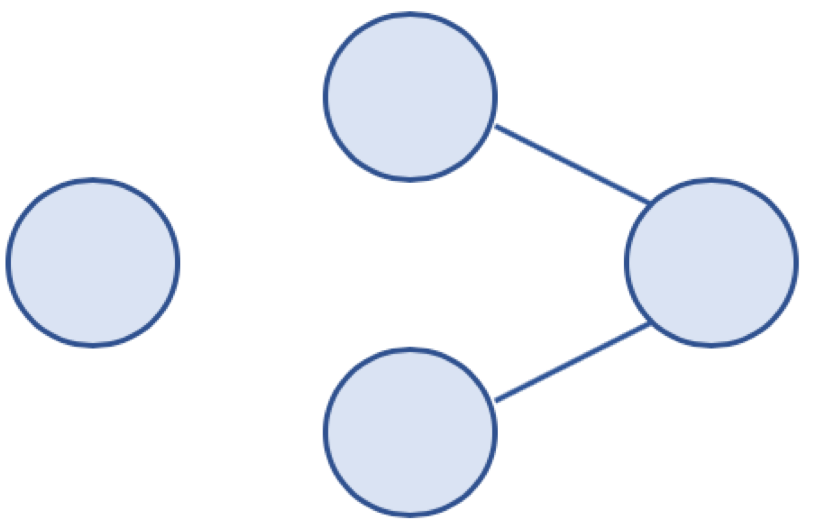
* 사이클 (Cycle) 과 비순환 그래프 (Acyclic Graph)
* 사이클 (Cycle)
* 단순 경로의 시작 노드와 종료 노드가 동일한 경우
* 비순환 그래프 (Acyclic Graph)
* 사이클이 없는 그래프
* 비순환 그래프 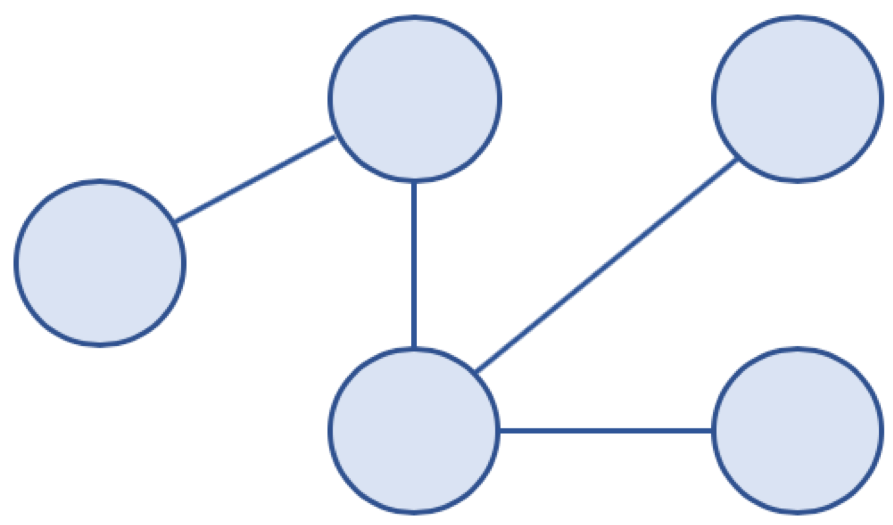
* 완전 그래프 (Complete Graph)
* 그래프의 모든 노드가 서로 연결되어 있는 그래프
* 완전 그래프 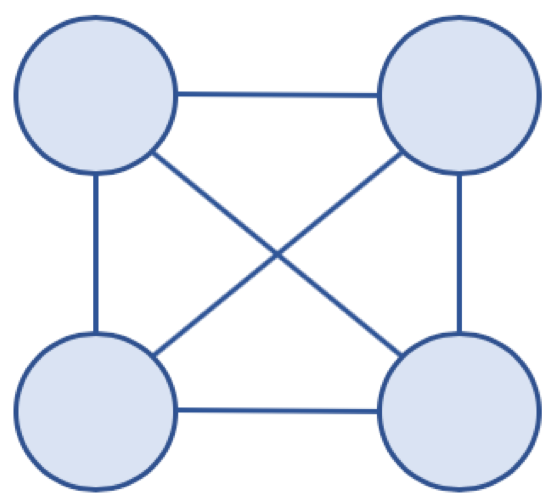
* 그래프(Grape)와 트리(Tree)의 차이
* 트리는 그래프 중에 속한 특별한 종류라고 볼 수 있음
| | 그래프 | 트리 |
| -------- | ------------------------------------- | --------------------------------- |
| 정의 | 노드와 노드를 연결하는 간선(무방향+방향)으로 표현되는 자료 구조 | 그래프의 한 종류, 방향성(화살표->)이 있는 비순환 그래프 |
| 방향성 | 방향 그래프, 무방향 그래프 둘다 존재함 | 방향 그래프만 존재함 |
| 사이클 | 사이클 가능함, 순환 및 비순환 그래프 모두 존재함 | 비순환 그래프로 사이클이 존재하지 않음 |
| 루트 노드 | 루트 노드 존재하지 않음(뭐가 루트 노드다 라고 딱 정의하지 않음) | 루트 노드 존재함 |
| 부모/자식 관계 | 부모 자식 개념이 존재하지 않음 | 부모 자식 관계가 존재함 |
### Reference