
알고리즘
Algorithm(알고리즘)이란 ?
어떤 문제를 풀기 위한 절차 또는 방법
어떤 문제에 대해 특정한 '입력'을 넣으면 원하는 '출력'을 얻을 수 있도록 만드는 프로그래밍을 말한다.
예를 들어, '라면 레시피'라는 알고리즘이 있다. 이 특정한 '입력'은 물 500ml를 몇분간끓이고, 면과 스프를 넣으면 라면이라는 '출력'을 얻는 알고리즘이다. 그런데, 라면은 사람마다 끓이는 스타일이 다를 수 있다. 누구는 찬물에 먼저 스프를 넣을 수 있고, 누구는 물을 350ml만 할 수도 있고 또 라면을 10분간 끓일 수도 있다. 결과물은 어찌됐건 같은 '라면'이다. 그러면 어찌됐건 똑같은 라면이라는 '출력'이 나왔다고 했을 때, 무슨 알고리즘을 택해야 할까의 기준은 이러하다.
어떤 방법이 더 시간을 적게 쓰는지, 또 어떤 방법이 더 공간을 적게 사용하는 지의 여부다. 시간복잡도/공간복잡도 라는 개념인데 나중에 살펴보겠다.

알고리즘 복잡도 계산 항목
시간 복잡도( 알고리즘 실행 속도 )
공간 복잡도( 알고리즘이 사용하는 메모리 사이즈 )
메모리 성능이 좋아짐에 따라서 공간복잡도보다는 시간 복잡도의 중요성이 커짐.
시간 복잡도를 결정하는 주요요인은 바로 반복문.
시간 복잡도 계산은 반복문이 핵심 요소임을 인지하고, 계산 표기는 최상/평균/최악 중, 최악의 시간인 Big-O 표기법을 중심으로 익히면 됨
알고리즘 성능 표기법
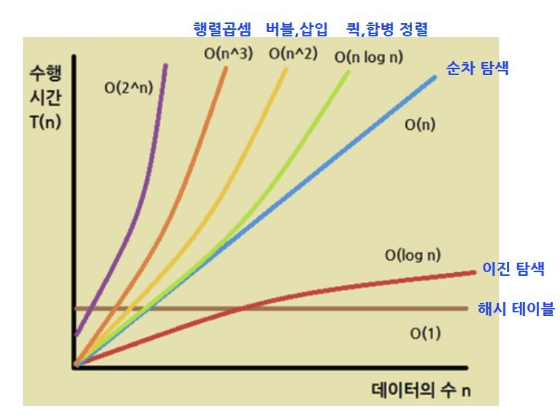
Big O (빅-오) 표기법: O(N)
알고리즘 최악의 실행 시간을 표기
가장 많이/일반적으로 사용함
아무리 최악의 상황이라도, 이정도의 성능은 보장한다는 의미이기 때문
Ω (오메가) 표기법: Ω(N)
오메가 표기법은 알고리즘 최상의 실행 시간을 표기
Θ (세타) 표기법: Θ(N)
오메가 표기법은 알고리즘 평균 실행 시간을 표기
Big-O (빅-오 표기법)
O(입력)
입력 n 에 따라 결정되는 시간 복잡도 함수
O(1), O($log n$), O(n), O(n$log n$), O($n^2$), O($2^n$), O(n!)등으로 표기함
입력 n 의 크기에 따라 기하급수적으로 시간 복잡도가 늘어날 수 있음
O(1) < O($log n$) < O(n) < O(n$log n$) < O($n^2$) < O($2^n$) < O(n!)
참고: log n 의 베이스는 2 - $log_2 n$

Bubble Sort(버블 정렬)
두 인접한 데이터를 앞에 있는 데이터가 뒤에 있는 데이터보다 크면 자리를 바꾸는 알고리즘
코드 최적화 작업 1,2까지 언제든지 구현하라고 하면 할 수 있어야 함.
알고리즘 분석
반복문이 두 개 -> O($n^2$)
완전 정렬된 상태일 때 -> O($n$)
Insertion Sort(삽입 정렬)
2번째 index부터 시작한다.
해당 값을 해당 값보다 앞에 있는 데이터와 비교해서 앞에가 더 작으면 멈추고 아니면 앞에가 더 작을 때까지 swap한다.
알고리즘 분석
반복문이 두 개 -> O($n^2$)
완전 정렬된 상태일 때 -> O($n$)
Selction Sort(선택 정렬)
먼저 최소값을 지정할 변수 minIndex 를 하나 만들고 for문을 끝까지 돌아서 최소값을 찾는다.
해당 최소값을 0번째 index와 swap한다.
다시 그 다음 최소값을 for문으로 찾고, 1번째 index와 swap한다.
다시 그 다음 최소값을 for문으로 찾고, 2번째 index와 swap한다.
그렇게 끝까지 한다.
알고리즘 분석
반복문이 두 개 -> O($n^2$)
완전 정렬된 상태일 때 -> O($n^2$)
Recursive Call(재귀 용법, 재귀 호출)
함수 안에서 동일한 함수를 호출하는 형태
동일한 함수를 계속 사용하면서 변수가 계속 생성되면 공간복잡도는 안좋을 수 있으나, 꽤나 직관적이게 문제를 해결 할 수 있어 여러 알고리즘에 쓰인다.
exit 코드를 명확히 하지 않으면 무한 순환에 빠질 수 있다.
재귀 호출은 스택의 전형적인 예이다.
함수가 내부적으로 스택처럼 관리되고 호출된다. 차례로 하나씩 열리고 차례로 하나씩 닫힌다.

Dynamic Programming(동적 계획법)
이름이 뭔가 어렵다. 동적 계획법? 다이내믹 프로그래밍? 그냥 DP라고 많이 부른다.
이름은 어렵지만 개념은 그렇게 어렵지 않다. 어떤 문제가 있을 때, 그것을 해결하기위해 문제를 잘게잘게 쪼개서 그 답을 상위 문제를 해결하는데 재사용하는 방법정도 라고 정의할 수 있다.
잘게 쪼갠 답을 저장해뒀다가 사용하는 것을 Memoization(메모이제이션)기법 이라고 한다.
위에 코드 예시해서 피보나치 수, 타일링, 파도반 수열을 재귀 호출을 사용한 경우와 비교해서 보면 되겠다. 코드가 공간복잡도 또는 여러번 실행되는 경우없이 최적화 되는 이점이 있다.
주로 사용되는 패턴이 있어서 그것만 숙지하면 어렵지 않다.
왜 사용하나요 ?
아래 피보나치수를 구하는 문제 해결 방법에서 재귀 호출을 사용하면, f(6)을 구할 때 f(5) -> 1회, f(4) -> 2회, f(3) -> 3회, f(2) -> 5회, f(1) -> 8회, f(0) -> 5회가 실행된다. 즉 코드가 계속 여러번 실행되는 것이다. 하지만 DP를 활용하면 이미 계산된 값 저장해서 재활용(메모이제이션 기법)할 수 있어 코드를 여러번 실행할 필요없이 최적화 된다. ( 사용 방법은 위에 코드 참고 )

실행 코드를 보며 이해해보기: 코드분석
Divide and Conquer(분할 정복)
문제를 나눌 수 없을 때까지 나누고(분할) 난 후에 각각을 해결(정복)하면서 다시 합병(조합)해서 문제의 답을 얻는 알고리즘
하향식 접근법으로 상위 해답을 구하기 위해 아래로 내려가면서 하위 해답을 구하는 방식이다.
일반적으로 재귀함수로 구현한다.
문제를 잘게 쪼갤 때, 부분 문제는 서로 중복되지 않는다.
대표적인 예로 병합정렬, 퀵정렬, 이진탐색을 사용 예시로 들 수있다.
분할과 정복 말고도 나누어서 정복한 문제를 다시 조합해줘야 하는 개념도 있다.
개념설명 ( 정복이라는 의미가 다시 합치는 것?이 아니라 말그대로 문제를 정복한다는 의미이다. 그리고 그걸 다시 조합해야 한다. )
분할(Divide): 문제를 더이상 분할할 수 없을 때까지 동일한 유형의 여러 하위 문제로 나눈다.
정복(Conquer): 가장 작은 단위의 하위 문제를 해결하여 정복한다.
조합(Combine): 하위 문제에 대한 결과를 원래 문제에 대한 결과로 다시 조합한다.
Dynamic Programming(동적 계획법) vs Divide and Conquer(분할 정복)
공통점
문제를 잘게 쪼개서, 가장 작은 단위로 분할한다.
차이점
Dynamic Programming
부분 문제는 중복되어, 상위 문제 해결 시 재활용됨
Memoization 기법 사용 (부분 문제의 해답을 저장해서 재활용하는 최적화 기법으로 사용)
Divide and Conquer
부분 문제는 서로 중복되지 않음
부분 문제가 중복되지 않으니 당연히 이미 부분 문제의 해답을 따로 저장해서 재활용하는 메모이제이션 기법 또한 사용하지 않는다.
Quick Sort(퀵 정렬)
Divide and Conquer(분할 정복) 개념을 사용한다.
재귀용법을 활용한 정렬 알고리즘이다.
정렬 알고리즘의 꽃이라고 불린다.
분할(Divide)
기준점(pivot 이라고 부름)을 정한다. 통상적으로는 그냥 첫번째 데이터로 한다.
기준점을 기준으로 보다 작은 데이터는 왼쪽(left), 큰 데이터는 오른쪽(right)으로 분할(Divide)한다.
기준점(pivot)은 리스트가 계속 쪼개질때마다 그 리스트의 첫번째 데이터로 계속 바뀐다.
병합 정렬(Merge Sort) 하고는 조금 다른 점이 합치면서 정렬했던 병합 정렬(Merge Sort)에 반해 Quick Sort는 pivot을 기준으로 나누면서 왼쪽/오른쪽으로 정렬한다.
재귀용법을 사용해서 다시 동일 함수를 호출하여 리스트가 1개 남을 때까지 분할(Divide)한다.



정복(Conquer)
이제 분할된 데이터를 다시 합치(Combine)는데, quickSort의 리턴값은 리스트이다. 그래서 아래의 모양대로 분할된 그대로 다시 리턴하면서 주루룩 더하게 되면 정렬된 데이터가 짜잔 하고 신기하게도 완성된다. ( 이미 분할(Divide) 하면서 정렬(Conquer)을 했기 때문이다. )
quickSort(left) + [pivot] + quickSort(right)
자세한 사항은 코드 예시를 참고하자.

알고리즘 분석
병합정렬과 유사, 시간복잡도는 O(n log n)
단, 최악의 경우
맨 처음 pivot이 가장 크거나, 가장 작으면
모든 데이터를 비교하는 상황이 나옴
O($n^2$)

Merge Sort(병합 정렬)
Divide and Conquer(분할 정복) 개념을 사용한다.
재귀용법을 활용한 정렬 알고리즘이다.
리스트를 절반으로 계속 분할(Divide)한다. 리스트가 1개가 남을 때까지 계속 한다.
그런 후에, 좌우를 비교해서 정렬(Conquer)하면서 합친(Combine)다.

알고리즘 분석
O(n log n)
다음을 보고 이해해보자. (어려우니 참고로만 알아둬도 괜찮다.)
몇 단계 깊이까지 만들어지는지를 depth 라고 하고 i로 놓자. 맨 위 단계는 0으로 놓자.
다음 그림에서 n/$2^2$ 는 2단계 깊이라고 해보자.
각 단계에 있는 하나의 노드 안의 리스트 길이는 n/$2^2$ 가 된다.
각 단계에는 $2^i$ 개의 노드가 있다.
따라서, 각 단계는 항상 $2^i * \frac { n }{ 2^i } = O(n)$
단계는 항상 $log_2 n$ 개 만큼 만들어짐, 시간 복잡도는 결국 O(log n), 2는 역시 상수이므로 삭제
따라서, 단계별 시간 복잡도 O(n) * O(log n) = O(n log n)

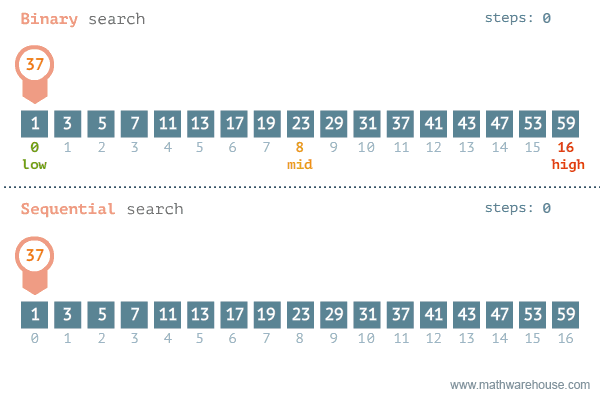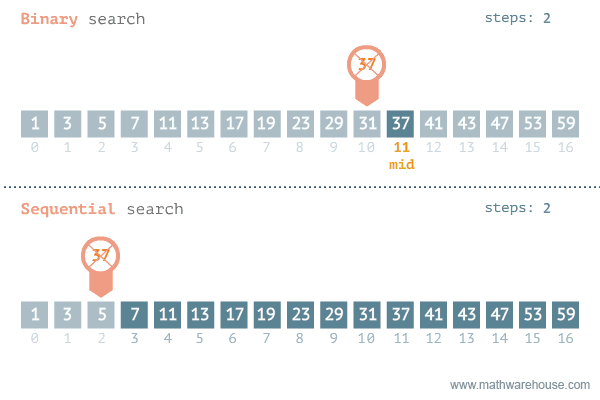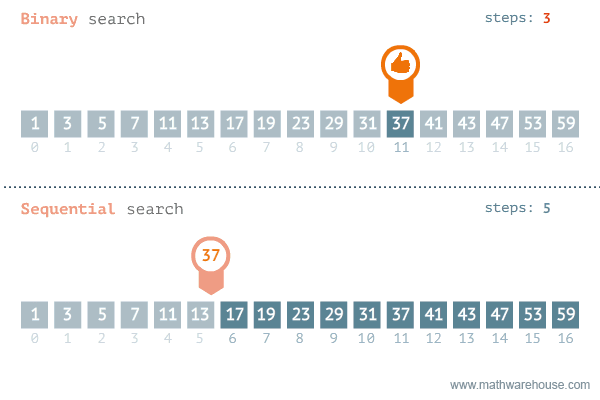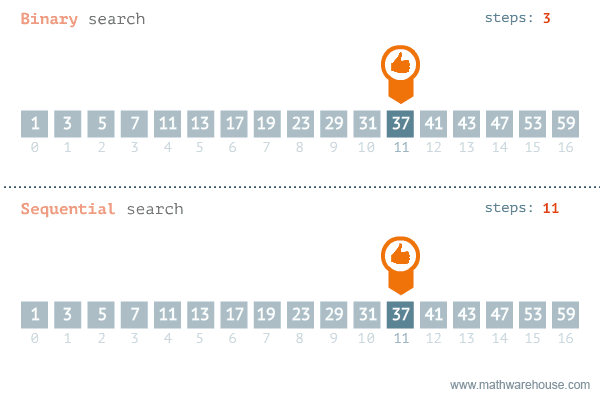
Sequential Search(순차 탐색)
탐색은 여러 데이터 중에서 원하는 데이터를 찾아내는 것을 의미
데이터가 담겨있는 리스트를 앞에서부터 하나씩 비교해서 원하는 데이터를 찾는 방법
이름에 비해 매우 쉬운 탐색 방법이다.
알고리즘 분석
최악의 경우 리스트 길이가 n일 때, n번 비교해야 함
O(n)
Binary Search(이진 탐색)
탐색할 자료를 둘로 나누어 해당 데이터가 있을만한 곳을 탐색하는 방법
Divide and Conquer(분할 정복) 개념을 사용한다.
재귀용법을 활용한 정렬 알고리즘이다.
정렬되어야 한다는 조건이 있다.
이진 탐색(Binary Search)과 순차 탐색(Sequential Search)
이진 탐색(Binary Search)과 이진 탐색 트리(Binary Search Tree)
공통점
이름이 비슷하다. 그래서 헷갈릴 수 있다.
둘 다 주로 검색 용도로 사용되는 알고리즘이다.
차이점
이진 탐색(Binary Search)
배열 자료구조를 사용한다.
데이터가 정렬된 상태에서 검색을 해야 한다는 조건이 있다.
이진 탐색 트리(Binary Search Tree)
트리 자료구조를 사용한다.
정렬과는 관계가 없고, 이진 탐색 트리만의 정책을 따른다.

알고리즘 분석
O(logn)
n개의 리스트를 매번 2로 나누어 1이 될 때까지 비교연산을 k회 진행
n X $\frac { 1 }{ 2 }$ X $\frac { 1 }{ 2 }$ X $\frac { 1 }{ 2 }$ ... = 1
n X $\frac { 1 }{ 2 }^k$ = 1
n = $2^k$ = $log_2 n$ = $log_2 2^k$
$log_2 n$ = k
빅 오 표기법으로는 k + 1 이 결국 최종 시간 복잡도임 (1이 되었을 때도, 비교연산을 한번 수행)
결국 O($log_2 n$ + 1) 이고, 2와 1, 상수는 삭제 되므로, O($log n$)
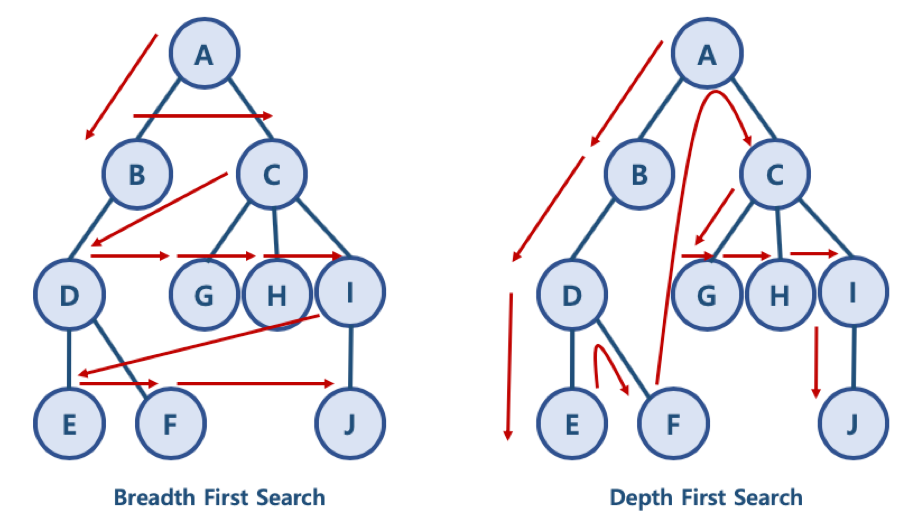
Breadth-First Search(너비 우선 탐색)
BFS 와 DFS 는 대표적인 그래프 탐색알고리즘
너비 우선 탐색 (Breadth First Search): 노드와 같은 레벨에 있는 노드들 (형제 노드들)을 먼저 탐색하는 방식
깊이 우선 탐색 (Depth First Search): 노드의 자식들을 먼저 탐색하는 방식
BFS/DFS 방식 이해를 위한 예제
BFS 방식: A - B - C - D - G - H - I - E - F - J
한 단계씩 내려가면서, 해당 노드와 같은 레벨에 있는 노드들 (형제 노드들)을 먼저 순회함
DFS 방식: A - B - D - E - F - C - G - H - I - J
한 노드의 자식을 타고 끝까지 순회한 후, 다시 돌아와서 다른 형제들의 자식을 타고 내려가며 순화함
A - B 로 가든, A - C 로 가든 방향은 상관없다. 깊이 부터 순회하는 정책만 잘 따르면 된다.
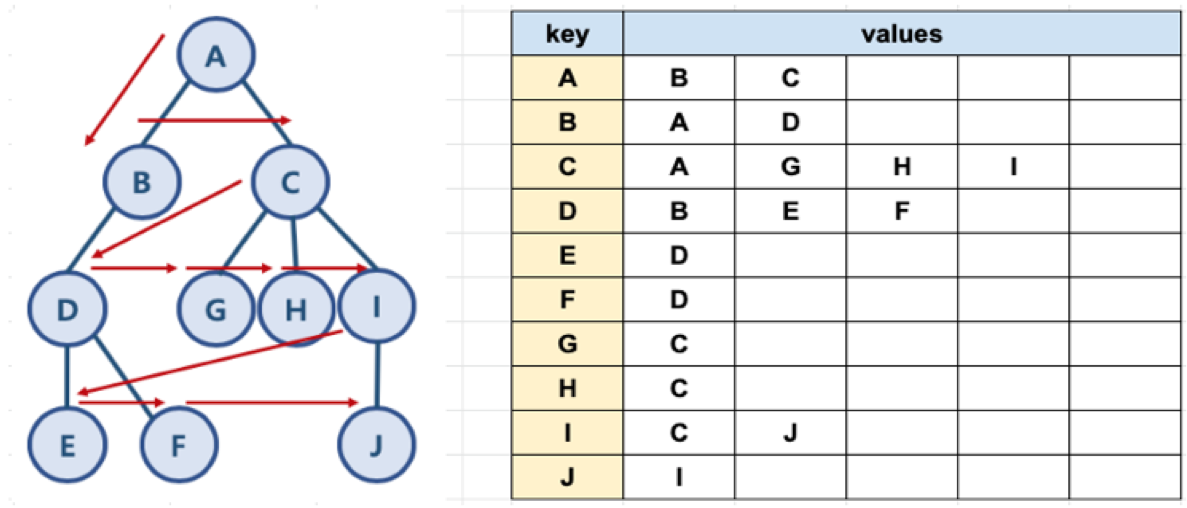
딕셔너리와 배열을 통해서 그래프를 표현할 수 있다.
큐 2개를 사용해서 아래의 순서에 따라 데이터를 넣으면 그래프를 구현할 수 있다.
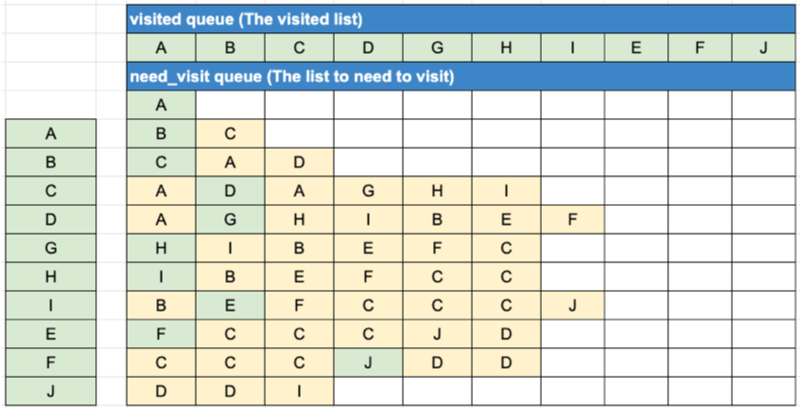
큐 2개(visited queue, need_visited queue)를 활용해서 데이터를 넣는 순서
맨처음 A를 need_visited queue에 넣는다.
need_visited queue에 들어가있는 데이터 중에 맨 앞에있는 데이터를 꺼낸다.( 데이터는 큐에서 없어진다. )
꺼낸 데이터가 visited queue에 있는지 확인한다.
확인해서 있다면
visited queue에 꺼낸 데이터를 넣는다.
그리고 visited queue 넣은 데이터의 키값에 해당되는 value를 need_visited queue 에 순서대로 넣는다. 다음턴으로 넘어간다.
확인해서 없다면
아무것도 하지 않는다. 다음턴으로 넘어간다.
need_visited queue에 들어가있는 데이터 중에 맨 앞에있는 데이터를 꺼낸다.( 데이터는 큐에서 없어진다. )
꺼낸 데이터가 visited queue에 있는지 확인한다. ( 아래생략 )
need_visited queue에 들어가있는 데이터 중에 맨 앞에있는 데이터를 꺼낸다.( 데이터는 큐에서 없어진다. )
꺼낸 데이터가 visited queue에 있는지 확인한다. ( 아래생략 ) ...
끝날때까지 진행한다.
need_visited queue 이 비게 된다면 그래프를 다 순회한 것이므로 종료한다.
시간 복잡도
O(n)과 같은 n을 사용하는 방법 말고 O(V + E)로 표시하는 시간복잡도를 갖는다.
노드 수: V
간선 수: E
위 코드에서 while need_visit 은 V + E 번 만큼 수행함
시간 복잡도: O(V + E)
Depth-First Search(깊이 우선 탐색)
BFS 와 DFS 는 대표적인 그래프 탐색알고리즘
너비 우선 탐색 (Breadth First Search): 노드와 같은 레벨에 있는 노드들 (형제 노드들)을 먼저 탐색하는 방식
깊이 우선 탐색 (Depth First Search): 노드의 자식들을 먼저 탐색하는 방식
BFS/DFS 방식 이해를 위한 예제
BFS 방식: A - B - C - D - G - H - I - E - F - J
한 단계씩 내려가면서, 해당 노드와 같은 레벨에 있는 노드들 (형제 노드들)을 먼저 순회함
DFS 방식: A - B - D - E - F - C - G - H - I - J
한 노드의 자식을 타고 끝까지 순회한 후, 다시 돌아와서 다른 형제들의 자식을 타고 내려가며 순화함
A - B 로 가든, A - C 로 가든 방향은 상관없다. 깊이 부터 순회하는 정책만 잘 따르면 된다.
딕셔너리와 배열을 통해서 그래프를 표현할 수 있다.

큐 1개, 스택 1개를 사용해서 아래의 순서에 따라 데이터를 넣으면 그래프를 구현할 수 있다.

큐(visited queue) 와 스택(need_visited stack)를 활용해서 데이터를 넣는 순서
맨처음 A를 need_visited stack에 넣는다.
need_visited stack에 들어가있는 데이터 중에 마지막에 있는 데이터를 꺼낸다.( 스택이니까. )
꺼낸 데이터가 visited queue에 있는지 확인한다.
확인해서 있다면
visited queue에 꺼낸 데이터를 넣는다.
그리고 visited queue 넣은 데이터의 키값에 해당되는 value를 need_visited stack에 넣는다. 다음턴으로 넘어간다.
확인해서 없다면
아무것도 하지 않는다. 다음턴으로 넘어간다.
need_visited stack에 들어가있는 데이터 중에 마지막에 있는 데이터를 꺼낸다.( 스택이니까. )
꺼낸 데이터가 visited queue에 있는지 확인한다. ( 아래생략 )
need_visited stack에 들어가있는 데이터 중에 마지막에 있는 데이터를 꺼낸다.( 스택이니까. )
꺼낸 데이터가 visited queue에 있는지 확인한다. ( 아래생략 ) ...
끝날때까지 진행한다.
need_visited stack 이 비게 된다면 그래프를 다 순회한 것이므로 종료한다.
시간 복잡도
O(n)과 같은 n을 사용하는 방법 말고 O(V + E)로 표시하는 시간복잡도를 갖는다.
노드 수: V
간선 수: E
위 코드에서 while need_visit 은 V + E 번 만큼 수행함
시간 복잡도: O(V + E)
Greedy Algorithm(탐욕 알고리즘)
최적의 해에 가까운 값을 구하기 위해 사용됨
여러 경우 중 하나를 결정해야할 때마다, 매순간 최적이라고 생각되는 경우를 선택하는 방식으로 진행해서, 최종적인 값을 구하는 방식
탐욕 알고리즘의 한계
탐욕 알고리즘은 근사치 추정에 활용
반드시 최적의 해를 구할 수 있는 것은 아니기 때문
최적의 해에 가까운 값을 구하는 방법 중의 하나임

'시작' 노드에서 시작해서 가장 작은 값을 찾아 leaf node 까지 가는 경로를 찾을 시에
Greedy 알고리즘 적용시 시작 -> 7 -> 12 를 선택하게 되므로 7 + 12 = 19 가 됨
하지만 실제 가장 작은 값은 시작 -> 10 -> 5 이며, 10 + 5 = 15 가 답
Dijkstra Algorithm(다익스트라 알고리즘)
그래프 자료구조를 사용한 두 노드를 잇는 최단거리를 찾는 알고리즘
가중치(Weight)그래프에서 간선(Edge)의 가중치 합이 최소가 되도록 하는 경로를 찾는 것이 목적이다.
최단 경로 문제의 종류
단일 출발 및 단일 도착 최단 경로 문제
그래프 내의 특정 노드 u 에서 출발, 또다른 특정 노드 v 에 도착하는 가장 짧은 경로를 찾는 문제
단일 출발 최단 경로 문제(SSP)
single-source shortest path problem
그래프 내의 특정 노드 u 와 그래프 내 다른 모든 노드 각각의 가장 짧은 경로를 찾는 문제
A, B, C, D 라는 노드가 있고 시작점을 A라고 하면 A - B, A - C, A - D 에 대한 최단경로를 찾는 문제
전체 쌍 최단 경로 문제(ASP):
all pairs shortest path problem
그래프 내의 모든 노드 쌍 (u, v) 에 대한 최단 경로를 찾는 문제
A - B, A - C, A - D, B - C, B - D...
변형이 많은 알고리즘인데 일반적으로는 2번을 뜻한다.
가장 개선된 변형인 우선순위 큐를 활용한 버전을 볼 것이고, 아래그림에서 A->B,C,D->E,F 식으로 순회하기 때문에 실질적으로 마치 너비우선탐색(BFS)처럼 순회한다.
다익스크라 알고리즘을 이해하기 위한 예제

초기화
첫 노드를 기준으로 배열을 생성하고, 초기값을 할당한다.
첫 노드의 초기값은 0, 나머지는 무한대로 저장한다.
우선순위 큐에 튜플 타입으로 (첫 노드, 0)을 먼저 넣는다.

A 노드 기준 거리 계산
우선순위 큐에서 하나를 뺀다. (처음이니 첫 노드가 꺼내진다.)
꺼낸 노드에서 갈 수 있는 노드는 B, C, D 이다. (F로는 못간다. 방향 그래프라서 화살표가 있다.)
꺼낸 노드에서 각 B, C, D 노드로 갈 수 있는 거리와 생성한 배열의 거리를 비교해서 더 짧으면 바꿔준다. 그렇지 않으면 바꾸지 않는다.
바꿔지면 큐에 넣는다. 다만 저 큐는 우선순위큐(min heap)이므로 늦게 넣었어도 가중치(weight)를 기준으로 넣을때마다 정렬된다.
첫 노드 기준 한바퀴를 다 돌았다.
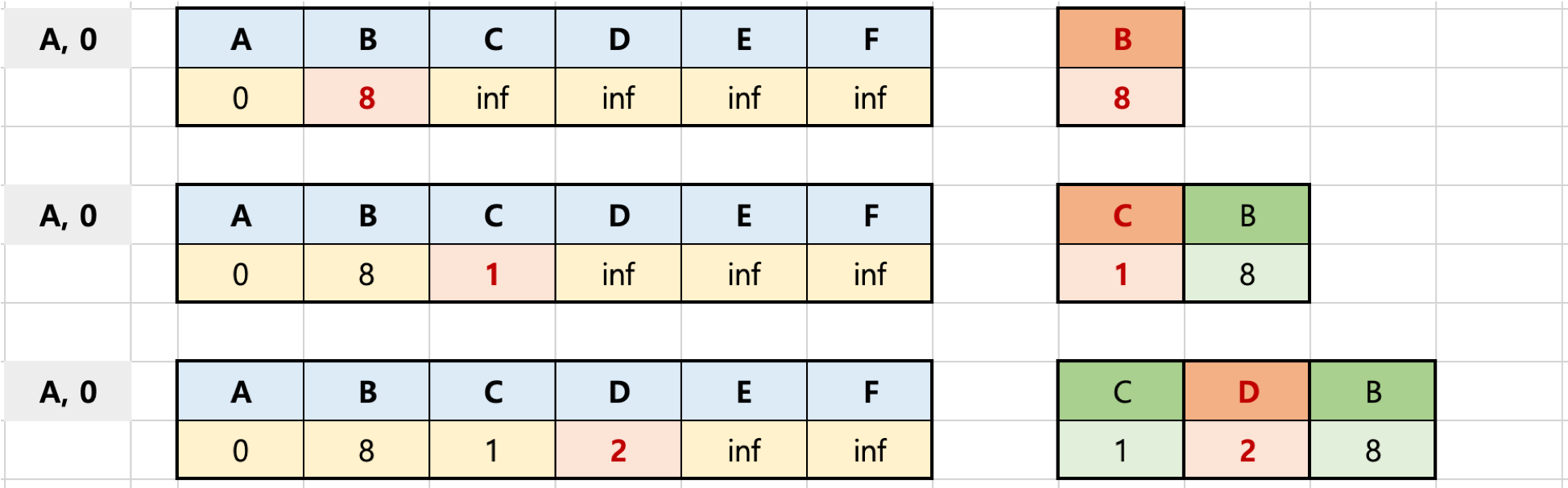
C 노드 거리 계산 (우선순위 큐에서 꺼낸 데이터)
우선순위 큐에서 데이터를 하나 꺼낸다. min heap 이므로 (C, 1)이 꺼내진다.
기존에 A를 기준으로 순회했다면, 이번에는 C를 기준으로 순회하는 것이다.
C를 기준으로 보자. C에서는 C->D, C->B가 있다.
C->D
지금 생성한 배열을 기준으로 보면 (A,0) (C,1) 이다. 이 말은 A->C까지의 거리가 1이라는 말이다.
그리고 C->D의 거리는 2이다. 그런데, A->D는 (A,0) (D,2)로 2이다. 즉, A->C->D가 A->D 보다 더 늦다.
이러면 아무것도 하지 않는다. 그냥 큐에서 데이터만 하나 빠진것이다.
C->B
C->B를 보자. 얘는 A->B는 8인데, A->C->B는 1+5 = 6이다.
이러면 아까전에 했던 것처럼 A->C->B 가 A->B 보다 낮으니 배열을 6으로 업데이트하고 (B,6)을 큐에 넣는다.
주의할 점은 실질적으로 큐에는 (6,B)로 들어간다. (데이터를 꺼낼때 앞에 거를 기준으로 빼오기 때문에) 또, 지금 그림을 보면 이미 (B,8)이 있다. 그럼에도 (B,6)으로 새로 들어가는 것이다.
자, 이제 C에서 갈 수 있는 방향은 다 돌았으니 한바퀴가 또 끝났다.

D 노드 거리 계산 (우선순위 큐에서 꺼낸 데이터)
같은 방식으로 진행한다.
D에서는 D->E, D->F가 있다.
배열에 현재 저장된 A->D가 2인데, 그림상으로 E까지는 2+3=5, F까지는 2+5=7이다. 하지만 배열에는 inf(무한대)가 저장되어 있다. 비교해서 당연히 거리가 더 짧으므로 배열을 바꿔주고 우선순위 큐에 넣어준다.
한바퀴가 또 끝났다.

E 노드 거리 계산 (우선순위 큐에서 꺼낸 데이터)
E 기준으로 진행한다.
배열을 보면 A->E는 5이다. 그리고 그림을 보면 E에서 갈 수 있는 곳은 F밖에 없고 거리는 1이다. 1+5인데 배열에는 A->F가 7로 되어있으므로 배열을 업데이트하고 큐에 데이터를 넣어준다.
한바퀴가 또 끝났다.

B,F 노드 거리 계산 (우선순위 큐에서 꺼낸 데이터)
B 기준으로 진행한다. B가 2개지만 weight가 제일 낮은 6이 최소힙에서 꺼내진다.
B 는 갈 수 있는 데가 없다 종료한다.
다시 데이터를 꺼낸다. F, 6이 나왔다.
F는 배열을 보니 A->F가 6인데, F->A 가 5이다. 하지만, A->A는 0이다. 따라서 아무것도 하지 않는다.
한바퀴가 또 끝났다. (사실상 두바퀴였나)

F,B 노드 거리 계산 (우선순위 큐에서 꺼낸 데이터)
F 기준으로 진행한다. (F,7)이 나왔다. 어차피 계산을 해도 바로 위에처럼 아무것도 안할 것이지만, 여기선 최적화를 진행한다.
뭐냐면, A->F는 6이다. 그리고 지금 꺼낸 큐에서 나온 데이터는 (F,7)이다. 그러면 큐에서 나온 데이터는 뭔짓을 해도 A->F보다 작을 수 는 없는 거다. 그렇지? 왜냐 A->F는 6이니까. 이후에 계산할 작업인 F->A는 어차피 둘 다 더할 값이기 때문이다. (만약에 F->A가 아니라 F->G 였더라도)
정리하면, 현재 배열의 거리가 큐에서 꺼낸 거리보다 작다면 그 이후를 계산할 필요없이 바로 다음 작업을 진행하면 된다.
F는 끝났고, 이제 B를 진행한다. 방금 말했던 것처럼 배열의 B는 6이고, 큐에서 꺼낸 데이터는 8이니 아무것도 진행하지 않는다.
종료
우선순위 큐가 비어있으니 종료한다.
현재 배열의 남아있는 데이터가 바로 첫 노드인 A를 기준으로 각 노드까지의 최단 경로이다.
이 방법의 장점은 우선순위 큐를 사용하므로, minheap에서 가장 짧은 거리가 먼저 나와서 그거 기준으로 계산하기 때문에 더 긴 거리의 루트에 대해서는 계산을 스킵할 수 있다.
무슨 말이냐면, 위에서 처럼 짧은 거리부터 계산을 하기 때문에 그것부터 계산해서 배열이 딱 세팅되어 있다. 그런데, 그 배열의 데이터보다 큰 데이터가 큐에서 나오면 그건 계산의 의미가 없으므로 스킵해버릴 수 있는 것이다.
시간 복잡도
위 다익스트라 알고리즘은 크게 다음 두 가지 과정을 거침
과정1: 각 노드마다 인접한 간선들을 모두 검사하는 과정
A를 기준으로하면 B,C,D를 꼭 다 한번씩 검사하고 C를 기준으로 하면 B,D를 검사하고 하는 식이다.
즉 모든 간선(Edge)들은 다 한번씩 검사한다. 그러므로 O(E).
과정2: 우선순위 큐에 노드/거리 정보를 넣고 삭제(pop)하는 과정
우선순위 큐에 가장 많은 노드, 거리 정보가 들어가는 시나리오는 그래프의 모든 간선이 검사될 때마다, 배열의 최단 거리가 갱신되고, 우선순위 큐에 노드/거리가 추가되는 것임
이 때 추가는 각 간선마다 최대 한 번 일어날 수 있으므로, 최대 O(E)의 시간이 걸리고, O(E) 개의 노드/거리 정보에 대해 우선순위 큐를 유지하는 작업은 $ O(log{E}) $ 가 걸림
따라서 해당 과정의 시간 복잡도는 $ O(Elog{E}) $
총 시간 복잡도
과정1 + 과정2 = O(E) + $ O(Elog{E}) $ = $ O(E + Elog{E}) = O(Elog{E}) $
heap의 시간 복잡도
우선순위 큐는 배열로 구현하면 쉽지만, heap으로 내부적으로 구현하는 것이 제일 효율이 좋다.
depth (트리의 높이) 를 h라고 표기한다면,
n개의 노드를 가지는 heap 에 데이터 삽입 또는 삭제시, 최악의 경우 root 노드에서 leaf 노드까지 비교해야 하므로 h=log2n 에 가까우므로, 시간 복잡도는 O(logn)
Minimum Spanning Tree(최소 신장 트리)
신장 트리(Spanning Tree)란?
모든 노드가 연결되어 있으면서 트리 자료구조의 속성을 만족하는 그래프
트리 자료구조의 속성이란, 노드와 브랜치를 이용해서 싸이클을 이루지 않도록 구성한다는 뜻
트리 또한 그래프의 한 종류
트리는 트리자료구조인데, 아래의 조건을 다 만족하는 트리
그래프의 모든 노드를 포함해야 한다.
모든 노드가 서로 연결되어야 한다.
싸이클이 존재하지 않아야 한다.
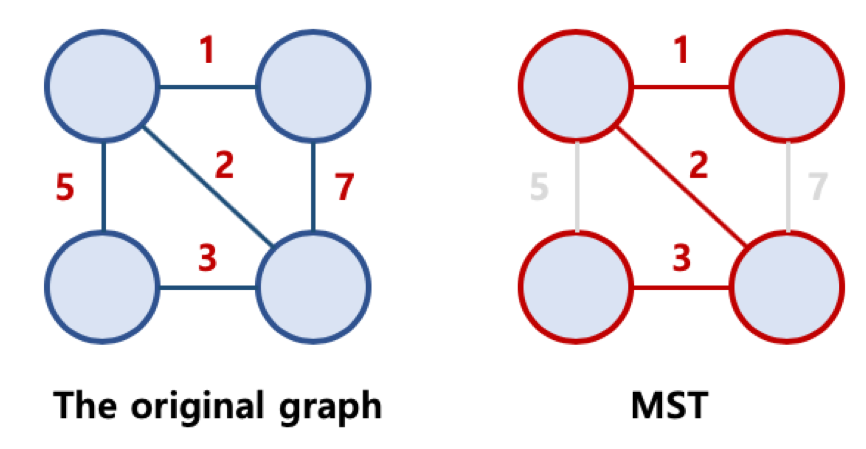
아래의 그림을 보면 더 이해가 쉽다. 왼쪽의 1개가 오리지널 그래프이고, 오른쪽의 8개가 1개의 오리지널 그래프에서 위의 3가지 조건을 만족하여 나올 수 있는 신장 트리들을 그려놓은 것이다.

최소 신장 트리(Minimum Spanning Tree)란?
그래프에 가중치(weight)가 있는 그래프가 있다고 하자.
그리고 그 녀석은 신장트리 조건을 만족한다. (모든 노드 포함, 연결, 싸이클 없음)
그리고 그렇게 가능한 신장트리 중에 가중치의 합이 최소인 신장트리를 최소 신장 트리라고 말한다.
아래 사진을 보면 오른쪽 MST가 신장 트리 중에 1+2+3으로 최소인 것을 볼 수 있다. 1+5+3 안되고, 1+5+7, 5+3+7도 안된다.
최소 신장 트리를 구하는 대표적인 알고리즘이 크루스칼(Kruskal’s), 프림(Prim's) 알고리즘(algorithm) 이다.
최소 신장 트리(Minimum Spanning Tree)는 왜 사용하나요 ?
우리가 알지 못핧 뿐, 우리 실생활에 아주 밀접하게 사용되고 있다. 가중치(weight)가 늘어난다는 것은 거리가 늘어난다는 것이고, 그것이 지하철이 됐든 전기선이 됐든 터무니 없는 금액의 공사 비용이 증가하는 것을 의미한다.
어떤 노드와 노드를 전부 연결하되, 가능한 최소의 비용으로 연결해야 하는 경우
도로 건설: 도시를 모두 연결하여 도로 길이 최소화
지하철 노선
고속도로, 국도
기찻길
통신: 전화선의 길이가 최소화 되도록 케이블망 구축
전기: 전력선의 길이가 최소화 되도록 전선망을 구축
네트워크: 라우터 경로를 설정하는데, 최적의 라우팅 경로를 선택
배관: 파이프를 모두 연결하되 총 길이를 최소로 연결
도시 하수도
대형 선박 내의 배관

Kruskal's Algorithm(크루스칼 알고리즘)
최소 신장 트리를 구하기 위한 알고리즘
정렬 후에 가중치가 낮은 간선부터 연결한다. (Greedy Algorithm 을 기반으로 하고 있다.)
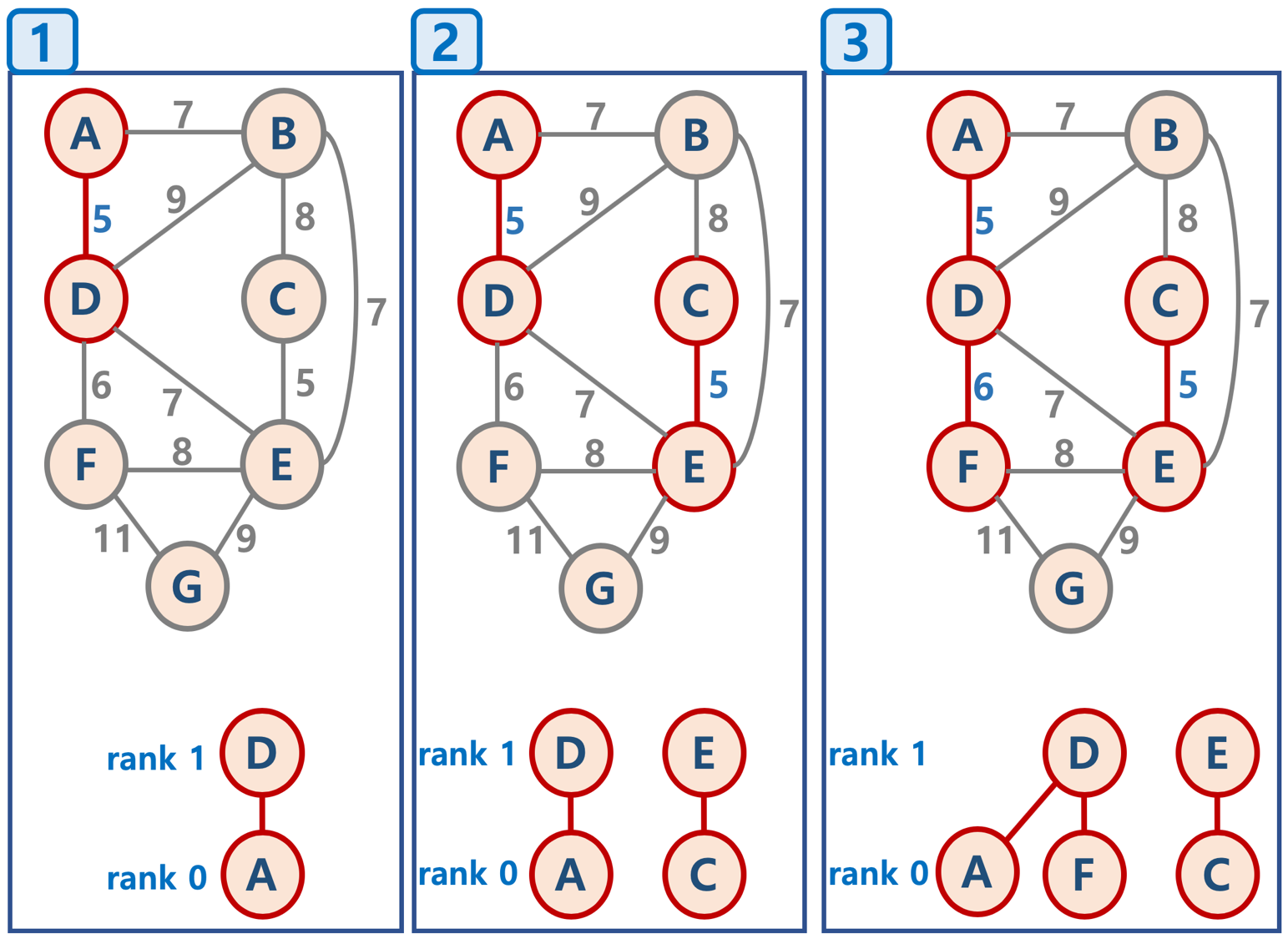
가중치(weight)를 기준으로 작은 것부터 노드를 연결하되, 싸이클이 생기면 그 노드는 연결하지 않는다. 모든 노드가 다 연결될 때까지 이 작업을 반복한다.
싸이클이 생기지의 여부를 판단하기 위해서 Union Find 알고리즘을 사용한다.

시간복잡도
O(E log E)
모든 정점을 독립적인 집합으로 만든다. -> O(V)
모든 간선을 비용을 기준으로 정렬하고, 비용이 작은 간선부터 양 끝의 두 정점을 비교한다. -> O(E log E)
퀵소트를 사용한다면 시간 복잡도는 O(n log n) 이며, 간선이 n 이므로 O(E log E)
두 정점의 최상위 정점을 확인하고, 서로 다를 경우 두 정점을 연결한다. (최소 신장 트리는 사이클이 없으므로, 사이클이 생기지 않도록 하는 것임)
union-by-rank 와 path compression 기법 사용시 시간 복잡도가 결국 상수값에 가까움, O(1)
따라서 O(V)보다 O(E)가 많으니 O(V)는 무시하고, O(E)보다는 O(E log E)가 크니까 결국엔 시간복잡도는 퀵소트를 사용하는 시간복잡도인 O(E log E)이다.

Union Find Algorithm(합집합 찾기 알고리즘)
트리 자료구조를 사용한다.
각자의 노드의 루트 노드를 비교해서 루트 노드가 같다면, 서로 같은 부분 집합 안에 들어가있다라는 것으로 싸이클 여부를 판단한다.
트리 구조이고, 항상 루트노드를 찾아 비교해야 하기 때문에 최적화 기법(union-by-rank, path compression)을 사용한다.
여기서는 크루스칼 알고리즘에서 싸이클이 생기는지의 여부를 판단하기 위해 쓰이나, 크루스칼 알고리즘에서만 사용되는 것은 아니다.
정확히는 Disjoint Set(서로소 집합)을 만들 때 사용하는 알고리즘이다.
공통 원소가 없는 두 집합이다.
예를 들어서 {1, 2, 3}과 {4, 5, 6}은 서로소이며 {1, 2, 3}과 {3, 4, 5}는 아니다.
Union Find 알고리즘 프로세스
초기화

n개의 원소를 개별집합으로 이뤄지도록 초기화 하는 작업
Union

두 개별 집합을 하나의 집합으로 합치는 작업, 두 트리를 하나의 트리로 합침
Find

여러 노드가 있을 때, 두 개의 노드를 선택해서 그 두개의 노드의 루트 노드를 찾는다.
위 그림에서 A, B를 예로 들면 A, B는 D라는 같은 루트 노드를 갖는다. 그러면 얘네들은 서로 같은 부분 집합 안에 들어가있다 라고 판단한다.
이 말은, D와 E를 루트 노드로 갖는 2개의 부분 집합을 합칠 때도 동일하게 적용된다. 루트 노드가 같지 않으면 싸이클이 없는 것으로 판단한다는 뜻이다.
Union Find 알고리즘 최적화
기본적으로 트리구조를 사용하기 때문에 성능을 고려할 필요가 있다.
각자의 노드의 루트 노드를 비교해서 루트 노드가 같다면, 서로 같은 부분 집합 안에 들어가있다라는 것으로 싸이클 여부를 판단한다.
Union의 순서에 따라서 최악의 경우 아래의 그림과 같이 링크드 리스트 형태가 될 수 있다.
그러면 시간복잡도가 O(n)이 될 수 있으므로 최적화 기법으로 union-by-rank 기법, path compression 기법을 사용한다.

Union By Rank 기법
Union Find 알고리즘 중에 Union 작업할 때 사용된다.
Union/Find 연산시의 시간복잡도를 O(n)에서 O(logN)으로 낮추기 위해서 사용한다.
밑에 있는 Path Compression 기법과 같이 사용하면 O(1)까지 낮출 수 있다.
2개의 부분 집합이 합쳐질 때, 어떻게 하면 높이를 작게하느냐에 초점을 맞춘 기법이다. (루트 노드를 찾는 시간을 줄이기 위해서)
Union By Rank 기법 프로세스
각 트리에 대해 rank(높이)를 저장해둔다.
두 개의 트리를 합칠 때, 두 트리의 rank가 다르다면 ?

rank가 작은 트리를 rank가 높은 트리의 자식노드로 붙인다.
이진트리가 아니기 때문에 어떻게 붙이든 상관이 없다.
(A,B,F)-(D)를 (C)-(E)-(G)에 그냥 붙였으면 최악의 경우 (A,B,F)-(D)-(C)-(E)-(G)로 rank가 4인 트리가 되지만, 이 기법을 쓰면 rank가 2로 만들 수 있다. (rank는 0부터)
두 트리의 rank가 같다면 ?

둘 중에 아무거나 한 쪽의 rank를 1 증가 시켜주고, 반대 쪽의 트리를 자식노드로 붙여준다.
초기화시, 모든 원소는 높이(rank) 가 0 인 개별 집합인 상태에서, 하나씩 원소를 합칠 때, union-by-rank 기법을 사용한다면,
높이가 h 인 트리가 만들어지려면, 높이가 h - 1 인 두 개의 트리가 합쳐져야 함
높이가 h - 1 인 트리를 만들기 위해 최소 n개의 원소가 필요하다면, 높이가 h 인 트리가 만들어지기 위해서는 최소 2n개의 원소가 필요함
따라서 union-by-rank 기법을 사용하면, union/find 연산의 시간복잡도는 O(N) 이 아닌, $ O(log{N}) $ 로 낮출 수 있음
Path Compression(경로 압축) 기법

Union Find 알고리즘 중에 Find 작업할 때 사용된다.
Find 작업을 한번 했다면, 그렇게 거쳐간 노드들을 루트 노드에 다이렉트로 연결되게 변경시키는 기법이다.
이진 트리가 아니기 때문에 자식 노드의 갯수는 상관이 없고, 이렇게 변경하면 이후부터는 Find시 1회만에 루트 노드를 찾을 수 있다.
Union By Rank 와 Path Compression 기법 사용시의 시간복잡도
O(1)이다. 수학적으로 이미 증명되었다.
$O(M log^*{N})$
$log^*{N}$ 은 다음 값을 가짐이 증명되었음
N이 $2^{65536}$ 값을 가지더라도, $log^*{N}$ 의 값이 5의 값을 가지므로, 거의 O(1), 즉 상수값에 가깝다고 볼 수 있음
- N$log^*{N}$
1
0
2
1
4
2
16
3
65536
4
$2^{65536}$
5
Prim's Algorithm(프림 알고리즘)
최소 신장 트리를 구하기 위한 알고리즘
크루스칼 알고리즘과 다른 점은 똑같이 Greedy Algorithm 을 기반으로 하는데, 주체가 다르다.
크루스칼 알고리즘이 단순 가중치를 기준으로 정렬을 해서 낮은 가중치부터 연결하고 그 다음 낮은 가중치를 연결 하는 식으로 동작했다고 하면, 프림 알고리즘은 시작할 첫번째 노드를 선택하고 선택한 노드를 기준으로 연결된 간선 중에 낮은 가중치가 있는 것 부터 연결, 그리고 새롭게 연결된 노드가 가지고 있는 간선들 중에 가중치가 낮은 것을 연결하는 식으로 동작한다.
프로세스
배열 2개를 만든다. '연결된 노드 리스트', '간선 리스트'
알고리즘을 시작한다. 여기서는 A로 시작했다. 처음이라 아무것도 없으니 '연결된 노드 리스트'에 A를 삽입한다.
'간선 리스트'에 A에 연결된 간선인 (5, A, D)와 (7, A, B)를 추가한다.
'간선 리스트'에서 데이터를 하나 추출(간선 리스트에서 사라짐)에서 하는데, 최소힙처럼 동작해서 가중치가 낮은 (5, A, D)가 추출된다.
그러면 목표는 D인데, D가 '연결된 노드 리스트'에 들어있으면? 싸이클로 판단하고 스킵한다. 없다면 '연결된 노드 리스트' 삽입한다. 그리고 '간선 리스트'에 D와 연결되어있는 간선들을 삽입한다. (6, D, F), (7, D, E), (8, D, B)
다시 '간선 리스트'에서 데이터를 하나 추출한다. 가중치가 가장 낮은게 나오니까 (6, D, F)이 추출된다.
5 번 작업을 진행한다. F는 없으니 추가한다. 간선 리스트에도 F와 연결된 간선들을 추가해준다.
6 번 작업을 진행한다. 가중치 7이 두 개지만, 그림 상에서는 (7, A, B)가 선택되었다.
B 추가, 간선리스트 추가
또 7이 두 개지만, 그림 상에서는 (7, B, E)가 선택되었다.
E 추가, 간선리스트 추가
가중치 5인 (5, E, B)가 선택되었다.
B 추가, 간선리스트 추가
가중치 7인 (7, D, E)가 나오지만 E는 이미 '연결된 노드 리스트'에 있다. 스킵된다.
가중치 8인 (8, F, E)가 나오지만 E는 이미 '연결된 노드 리스트'에 있다. 스킵된다.
가중치 8인 (8, B, C)가 나오지만 C는 이미 '연결된 노드 리스트'에 있다. 스킵된다.
이런 식으로 반복된다. 언제까지? 간선리스트가 빌 때까지.
간선리스트가 비었다. 최소 신장 트리가 완성되었고 알고리즘이 종료된다.



시간복잡도
최악의 경우, while 구문에서 모든 간선에 대해 반복하고, 최소 힙 구조를 사용하므로 O($ElogE$) 시간 복잡도를 가짐
개선된 프림 알고리즘
코드는 위의 링크 참고(파이썬)
간선이 아닌 노드를 중심으로 우선순위 큐를 적용하는 방식
초기화 - 정점:key 구조를 만들어놓고, 특정 정점의 key값은 0, 이외의 정점들의 key값은 무한대로 놓음. 모든 정점:key 값은 우선순위 큐에 넣음
가장 key값이 적은 정점:key를 추출한 후(pop 하므로 해당 정점:key 정보는 우선순위 큐에서 삭제됨), (extract min 로직이라고 부름)
해당 정점의 인접한 정점들에 대해 key 값과 연결된 가중치 값을 비교하여 key값이 작으면 해당 정점:key 값을 갱신
정점:key 값 갱신시, 우선순위 큐는 최소 key값을 가지는 정점:key 를 루트노드로 올려놓도록 재구성함 (decrease key 로직이라고 부름)
개선된 프림 알고리즘 구현시 고려 사항
우선순위 큐(최소힙) 구조에서, 이미 들어가 있는 데이터의 값 변경시, 최소값을 가지는 데이터를 루트노드로 올려놓도록 재구성하는 기능이 필요함
구현 복잡도를 줄이기 위해, heapdict 라이브러리를 통해, 해당 기능을 간단히 구현
개선된 프림 알고리즘의 시간 복잡도: $O(ElogV)$
최초 key 생성 시간 복잡도: $O(V)$
while 구문과 keys.popitem() 의 시간 복잡도는 $O(VlogV)$
while 구문은 V(노드 갯수) 번 실행됨
heap 에서 최소 key 값을 가지는 노드 정보 추출 시(pop)의 시간 복잡도: $O(logV)$
for 구문의 총 시간 복잡도는 $O(ElogV)$
for 구문은 while 구문 반복시에 결과적으로 총 최대 간선의 수 E만큼 실행 가능 $O(E)$
for 구문 안에서 key값 변경시마다 heap 구조를 변경해야 하며, heap 에는 최대 V 개의 정보가 있으므로 $O(logV)$
일반적인 heap 자료 구조 자체에는 본래 heap 내부의 데이터 우선순위 변경시, 최소 우선순위 데이터를 루트노드로 만들어주는 로직은 없음. 이를 decrease key 로직이라고 부름, 해당 로직은 heapdict 라이브러리를 활용해서 간단히 적용가능
따라서 총 시간 복잡도는 $O(V + VlogV + ElogV)$ 이며,
O(V)는 전체 시간 복잡도에 큰 영향을 미치지 않으므로 삭제,
E > V 이므로 (최대 $V^2 = E$ 가 될 수 있음), $O((V + E)logV)$ 는 간단하게 $O(ElogV)$ 로 나타낼 수 있음
Kruskal's(크루스칼) vs Prim's(프림)
사용 용도가 다를 수 있다.
크루스칼 알고리즘은 일단 전체 간선의 가중치를 다 알고 있다는 가정 하에 그걸 정렬해서 연결하는 방식
프림 알고리즘은 일부 가중치는 모를 때? 또는 한정된 정보 내에서 하나씩 선택해가면서 추가되는 정보에 따라서 연결하는 방식
프림 알고리즘은 개선된 버전이 있다. 크루스칼 알고리즘 시간복잡도(O(E log E)), 일반 프림 알고리즘 시간복잡도(O(E log E))에 비해 개선된 버전은 (𝑂(𝐸𝑙𝑜𝑔𝑉))로 더 효율적이다. (E > V 이므로 (최대 𝑉2=𝐸 가 될 수 있음))
Backtracking(백트래킹)
알고리즘은 아니고 일종의 문제를 푸는 전략이다.
제약 조건 만족 문제에서 사용한다.
모든 경우의 수(후보군)을 상태 공간 트리(State Space Tree)로 표현한다.
상태 공간 트리란, 문제 해결 과정의 중간 상태를 각각의 노드로 나타낸 트리인데 몰라도 된다. 전혀. 아래 그림이 상태 공간 트리.
컨셉이 트리 느낌으로 한다는 것이지 실제 코드 구현에서 트리를 만들거나 하지는 않는다.
각 후보군을 DFS 방식으로 확인한다.
조건이 맞는지를 검사하는 것을 Promising, 조건이 맞지 않으면 해당 트리를 끊어버리는 것을 Pruning(가지치기)라고 한다.
제약 조건이 전부 다 맞아야만 하는 문제에서 Pruning 함으로써 그 아래의 트리는 탐색해도 되지 않아 시간을 절약할 수 있다.
프로세스 설명 ( 문제와 같이 이해하는 것이 더 쉽다. 아래로 내려가자. )
예를 들어, 조건이 이런식이다 a, b, e, h가 다 홀수인지 확인해라.
그러면 a를 검사하고 b를 검사하고 e를 검사하고 h를 검사하는 식이 제일 효율적이다. (DFS 깊이 우선 탐색)
그런데 a는 홀수인데, b는 짝수이다? 그러면 정답이 아니다. 그러면 a-b 사이의 간선을 끊어버린다. 그럼 b 이하 트리는 검색할 필요도 없어진다.
이게 전부다. 검사하는걸 Promising, 가지치기 하는 것을 Pruning 이라고 부른단다.
이것을 Backtracking(백트래킹 또는 퇴각검색)전략이라고 부르는 이유이다.

N Queen 문제 이해

대표적인 백트래킹 문제이다.
뭐냐면, 체스에서 퀸은 아래 그림과 같이 굉장히 유능하게 움직일 수 있다. 그리고 문제는 "NxN 크기의 체스판에서 N개의 퀸을 배치한다고 했을 때, 서로 공격할 수 없도록 배치할 수 있는 경우의 수를 구해라." 이다.
화살표 오른쪽 사진이 하나의 예시이다.
Prunning(가지치기)

막연하나? 그럴 수 있다. 근데 이렇게 생각해보자. 저 문제를 배열로 표현하면 오른쪽 사진과 같다.
그리고 또 왼쪽 사진처럼 트리로 표현할 수도 있을 것 같다. 그럼 배운 것처럼 회색 동그라미는 조건을 만족하지 않으므로 무시하고 가지를 쳐버릴 수 있을 것이다. 이 부분은 그냥 저걸 배열로 표현할 수 있고, 그렇게 되면 가지치기를 할 수 있다 정도 까지만 이해하면 되겠다.
컨셉이 트리 느낌으로 한다는 것이지 실제 코드 구현에서 트리를 만들거나 하지는 않는다. 괜히 어렵게 표현하는 것이다.
그러면 제약 조건을 만족하는 방법이 뭘까? 내려가보자.
Promising(조건체크)

퀸은 겹치지 않아야 하므로 한줄에는 1개만 있어야 하고, 수직/대각선 이동이 다 가능하다.
그렇다면, 위에 만든 배열로 조건을 생성할 수 있다.
수직체크 : current_column - queen_column != 0 이어야 한다.
대각선체크 : abs(queen_column - current_column) != current_row - queen_row 이어야 한다.
이 부분 헷갈릴 수 있어서 따로 적어보겠다. 위 사진을 예로 들어보자. 퀸 위치(0,1), 내 위치(1,2)라고 하자.
그러면 튜플의 앞에 것의 차이(음수가 나올 수 있으므로 절대값 사용)인 abs(queen_column - current_column) 와 뒤에 것의 차이 current_row - queen_row 가 같으면 겹친다는 거다. 즉 달라야 된다는 거다.
공식으로 굳이 따지자면, abs(0 - 1) != 2 - 1 이어야 하는데 1 == 1 로 같다. 그러면 조건을 만족하지 못하는 것이다.
Reference
https://velog.velcdn.com/images/dev_kickbell/post/f4c3753a-b41a-43f7-86ab-f9ee661ae089/image.png
{kind=link}
https://visualgo.net/en/sorting
Last updated